
get()、chunk()、lazy()、cursor()の理解(Laravel)
紹介
データをクエリする際、いくつかの要因がアプリケーションのパフォーマンスに影響を与える可能性があります。適切に使用しないと、RAMを大量に消費し、ページの読み込み速度が著しく低下することがあります。
パフォーマンス最適化のために Laravel Octane を活用することに加えて、Laravel はケースに応じて効率的にデータクエリを実行するためのさまざまなメソッドを提供しています。本記事では、Laravel 11 と MySQL を使用していくつかの例を示します。
各メソッドの概要
- get(): クエリを実行し、すべてのデータを PHP メモリに読み込む。
- chunk(): データをチャンク(小分け)して順番に処理する。
- lazy(): chunk() に似ているが、PHP Generator を使用してよりメモリ効率が良い。
- cursor(): データベースバッファから1レコードずつ取得し、メモリを節約する。
get()
Laravel の get() メソッドはクエリを実行し、結果全体を Collection 形式で PHP メモリにロードします。
- クエリを即時に実行する。
- すべてのデータを一度に読み込むため、メモリ効率は悪い。
- map()、filter() などの Collection メソッドが使用可能。
- リレーションの Eager Load に対応。
⚠️ 注意: 小規模なデータセットに対してのみ使用を推奨。
🧪 例:すべての employees を取得
Laravel:
$employees = Employee::get();
実行される SQL:
SELECT * FROM employees;
RAM 使用量:
php.ini にて memory_limit = 128MB に設定されている場合、employees テーブルに 300,000 行があると、get() を使用すると「Allowed memory size of 134217728 bytes exhausted」というエラーが発生します。これは、許容メモリを超過するためです。
実際の例では、以下のようなデータ構造で最大約 70,000 行までしか取得できませんでした。
chunk()
chunk() メソッドは、データを小さなグループ(チャンク)に分割し、各チャンクを順番に処理するために使用されます。大量データを扱う場合にメモリ節約のため有効な手法です。
- 大量データに対して、段階的に処理できる場合に推奨されます。
- Collection の map() や filter() といったメソッドが利用可能。
- リレーションの Eager Load にも対応。
🧪 例:500 件ずつ employees を処理する
Laravel:
Employee::chunk(500, function ($employees) { foreach ($employees as $employee) { echo $employee->first_name . "\n"; } });
実行される SQL:
Chunk 1: SELECT * FROM `employees` ORDER BY `employees`.`emp_no` ASC LIMIT 500 OFFSET 0; Chunk 2: SELECT * FROM `employees` ORDER BY `employees`.`emp_no` ASC LIMIT 500 OFFSET 500; Chunk 3: SELECT * FROM `employees` ORDER BY `employees`.`emp_no` ASC LIMIT 500 OFFSET 1000;
RAM 使用量:
300,000 行のデータに対し、1チャンク 500 件で約 6.07MB のメモリを消費します。
⚠️ 注意: 特定のカラムに基づいてフィルタリングしつつ、その同じカラムの値を処理中に更新する場合、期待しないデータスキップや不整合が発生する可能性があります。
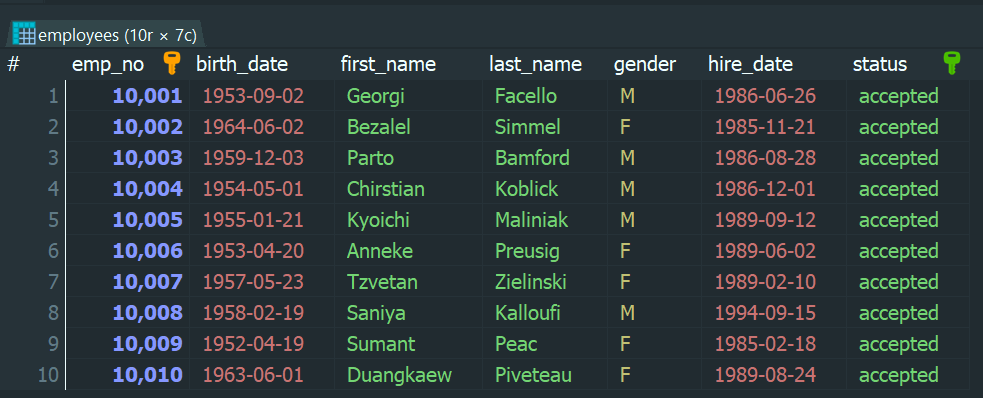
🧪 例:status が ‘accepted’ の employees を 2 件ずつ処理して ‘pending’ に更新する
Laravel:
Employee::where('status', 'accepted')->chunk(2, function ($employees) { foreach ($employees as $employee) { $employee->status = 'pending'; $employee->save(); } });
実行される SQL:
Chunk 1: select * from `employees` where `status` = 'accepted' order by `employees`.`emp_no` asc limit 2 offset 0; Chunk 2: select * from `employees` where `status` = 'accepted' order by `employees`.`emp_no` asc limit 2 offset 2;
更新前のデータ:
更新後のデータ:
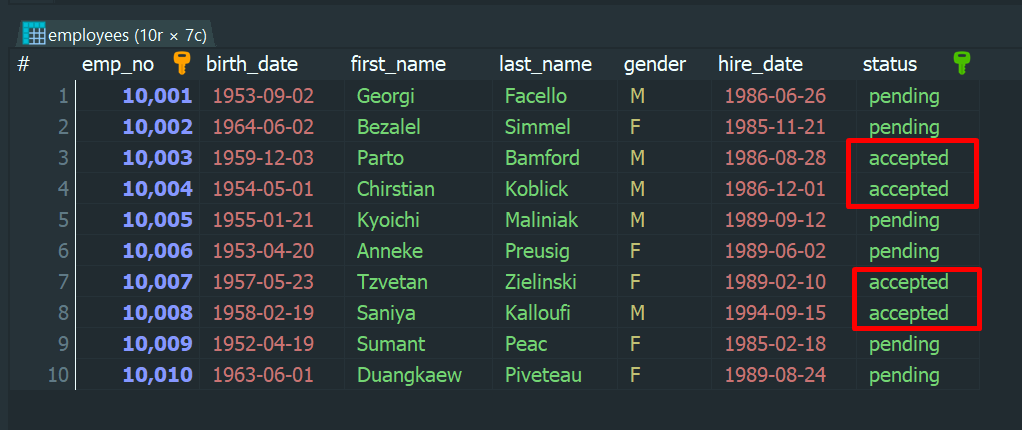
問題点: emp_no が 10,003・10,004・10,007・10,008 の employees が ‘pending’ に更新されていない。
原因:chunk の 1 回目が完了した時点で、emp_no が 10,003・10,004 の 2 件はすでに ‘pending’ に更新されています。この時点で、status = ‘accepted’ のレコード数は 8 件に減っています。
その後、chunk の 2 回目が OFFSET 2 で実行されると、10,003・10,004 の代わりに 10,005・10,006 が取得されて更新されます。つまり、10,003・10,004 の 2 件が意図せずスキップされ、同様に 10,007・10,008 もスキップされる結果になります。
解決策:OFFSET を使用する代わりに、chunkById() メソッドを使用することで、前回のチャンクの最後の ID を基準に、次のデータを取得することができます。これにより、更新中にデータの取りこぼしを防ぐことができます。
Laravel:
Employee::where('status', 'accepted')->chunkById(2, function ($employees) { foreach ($employees as $employee) { $employee->status = 'pending'; $employee->save(); } }, 'emp_no');
実行される SQL:
Chunk 1: select * from `employees` where `status` = 'accepted' order by `emp_no` asc limit 2 Chunk 2: select * from `employees` where `status` = 'accepted' and `emp_no` > 10002 order by `emp_no` asc limit 2 Chunk 3: select * from `employees` where `status` = 'accepted' and `emp_no` > 10004 order by `emp_no` asc limit 2
lazy()
lazy() メソッドは、LazyCollection を返すことで、メモリを節約しながら順次レコードを処理することができます。
chunk() と異なり、callback 関数は不要で、内部的には cursor() に近い動作をします。
- Collection の map()、filter() メソッドが利用可能。
- リレーションの Eager Load にも対応。
- get() のように全データをメモリに読み込まない。
🧪 例:status が ‘accepted’ の employees を ‘pending’ に更新する
Laravel:
$employees = Employee::where('status', 'accepted')->lazy(2); foreach ($employees as $employee) { $employee->status = 'pending'; $employee->save(); }
⚠️ 注意:ループ中にレコードを更新する場合、lazy() も chunk() 同様に OFFSET のズレにより問題が発生する可能性があります。そのため、lazyById() を使用することで安全に処理できます。
$employees = Employee::where('status', 'accepted')->lazyById(2, 'emp_no'); foreach ($employees as $employee) { $employee->status = 'pending'; $employee->save(); }
RAM 使用量:
300,000 行のデータに対し、lazy 500 件ずつで約 6.42MB のメモリを消費します。
cursor()
cursor() メソッドは、1 つの SQL クエリで実行され、結果を PHP メモリに一括で読み込むのではなく、1 件ずつデータベースバッファから取得します。大量データでも効率よく処理が可能です。
- 大量データの処理に適しています。
- 1 件ずつ処理されるため、Collection の map() や filter() は利用できません。
- リレーションの Eager Load にも対応していません。
🧪 例:すべての employees の first name を出力する
Laravel:
foreach (Employee::cursor() as $employee) { echo $employee->first_name . "\n"; }
実行される SQL:
SELECT * FROM employees;
RAM 使用量:
300,000 行のデータに対して使用メモリは約 1.87MB。
⚠️ 注意:
cursor() は、常に 1 件のレコードだけを PHP メモリに保持することでメモリ消費を最小化しますが、PDO ドライバの仕様により、大量データの場合でも全件を内部的に読み込む動作をする可能性があります。そのため、場合によってはメモリ枯渇(memory exhausted)が発生します。
このようなケースでは、以下のようなアプローチで回避可能です:
- クエリ自体の最適化(必要なカラムのみ取得など)
- ページネーションの導入(一定件数ずつ処理)
- Queue を活用したストリーミング処理
- ジョブを並列実行して分散処理
まとめ
| メソッド | データの読み込み方法 | メモリ使用量 | Collection 使用可 | Eager Load 対応 |
| get() | 全データを一括で読み込む | 高(大規模データでは OOM の危険) | ○ | ○ |
| chunk() | LIMIT/OFFSET による分割読み込み | get() より低 | ○ | ○ |
| lazy() | Generator により逐次処理 | chunk() よりさらに低 | ○ | ○ |
| cursor() | DB バッファから 1 件ずつ取得 | 最も低いが、PDO の制約あり | × | × |
 | Huỳnh Hữu Phát Developer |
今すぐ応募
福利厚生

社員の感情・願望を理解しているので、リバークレーンベトナムは特に年2回の定期昇給制度を設けています。毎年6月と12月に評価を行い、毎年1月と7月に給与が変更されます。また、社員は月次と年次の優秀な個人には定期的な業績賞与が別で支給されます。



チームビルディング・ファミリーデー・お夏休み・中秋節などのイベントはチーム内のメンバーが接続出来るしお互いに自分のことを共有出来る機会です。ご家族員に連携する際にはそれも誇りに言われています。



