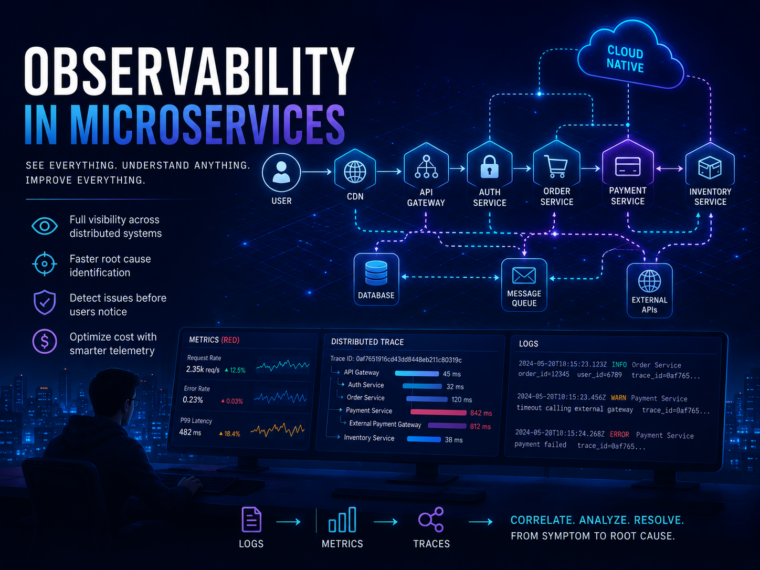
Observability trong Hệ Thống Phân Tán
Khi các hệ thống phần mềm chuyển dịch từ kiến trúc Monolithic sang Microservices và Cloud-Native, độ phức tạp trong vận hành bắt đầu tăng lên theo cấp số nhân. Trong môi trường phân tán, chỉ một độ trễ nhỏ từ API backend cũng có thể gây ra hiệu ứng domino, dẫn đến suy giảm trải nghiệm người dùng và ảnh hưởng trực tiếp đến doanh thu.
Trong bối cảnh đó, câu hỏi đặt ra không còn là:
“Hệ thống có đang chạy không?”
mà là:
“Điều gì đang thực sự xảy ra bên trong hệ thống?”
Để trả lời được câu hỏi này, Monitoring truyền thống là chưa đủ. Các tổ chức hiện đại cần một chiến lược Observability toàn diện nhằm:
- Xác định nguyên nhân gốc rễ (Root Cause) nhanh chóng
- Giảm thời gian khôi phục sự cố (MTTR – Mean Time To Recovery)
- Phát hiện vấn đề trước khi người dùng nhận ra
- Kiểm soát chi phí telemetry ở quy mô lớn
1. Điểm Mù Của Monitoring Truyền Thống
Trong nhiều năm, các đội vận hành chủ yếu dựa vào Infrastructure Monitoring để giám sát:
- CPU
- RAM
- Disk IO
- Network
Tuy nhiên, trong kiến trúc hiện đại, một request có thể đi qua rất nhiều thành phần:
Browser → CDN → Load Balancer → API Gateway → Authentication Service → Payment Service → Database→ External APIs
Một tình huống phổ biến trong production:
- Người dùng không thể thanh toán
- Dashboard hạ tầng vẫn báo “Healthy”
- CPU và RAM gần như không có bất thường
Monitoring truyền thống chỉ cho thấy hệ thống vẫn đang hoạt động. Tuy nhiên, một hệ thống “healthy” về mặt hạ tầng không đồng nghĩa với việc trải nghiệm người dùng đang thực sự ổn định.
Root cause thực tế có thể nằm ở:
- Network latency giữa các microservices
- Dependency chain bị timeout
- Queue backlog
- Database connection pool exhausted
- External API phản hồi chậm
Đây chính là giới hạn lớn nhất của Monitoring truyền thống: nó chỉ có thể đo lường những vấn đề đã được dự đoán từ trước.
2. Monitoring vs Observability
Để không bị nhầm lẫn về mặt khái niệm, cần xác định rõ ranh giới giữa Monitoring và Observability.
- Monitoring (Giám sát): Trả lời câu hỏi “Cái gì đang xảy ra?” dựa trên các chỉ số định trước.
- Observability (Khả năng quan sát): Trả lời câu hỏi “Tại sao nó lại xảy ra?” bằng cách cho phép kỹ sư đặt những câu hỏi động vào hệ thống để điều tra các lỗi dị thường (Unknown unknowns).
| Monitoring | Observability |
|---|---|
| Trả lời “Điều gì đang xảy ra?” | Trả lời “Tại sao nó xảy ra?” |
| Dựa trên metrics định trước | Điều tra các vấn đề bất thường |
| Reactive | Exploratory |
| Known unknowns | Unknown unknowns |

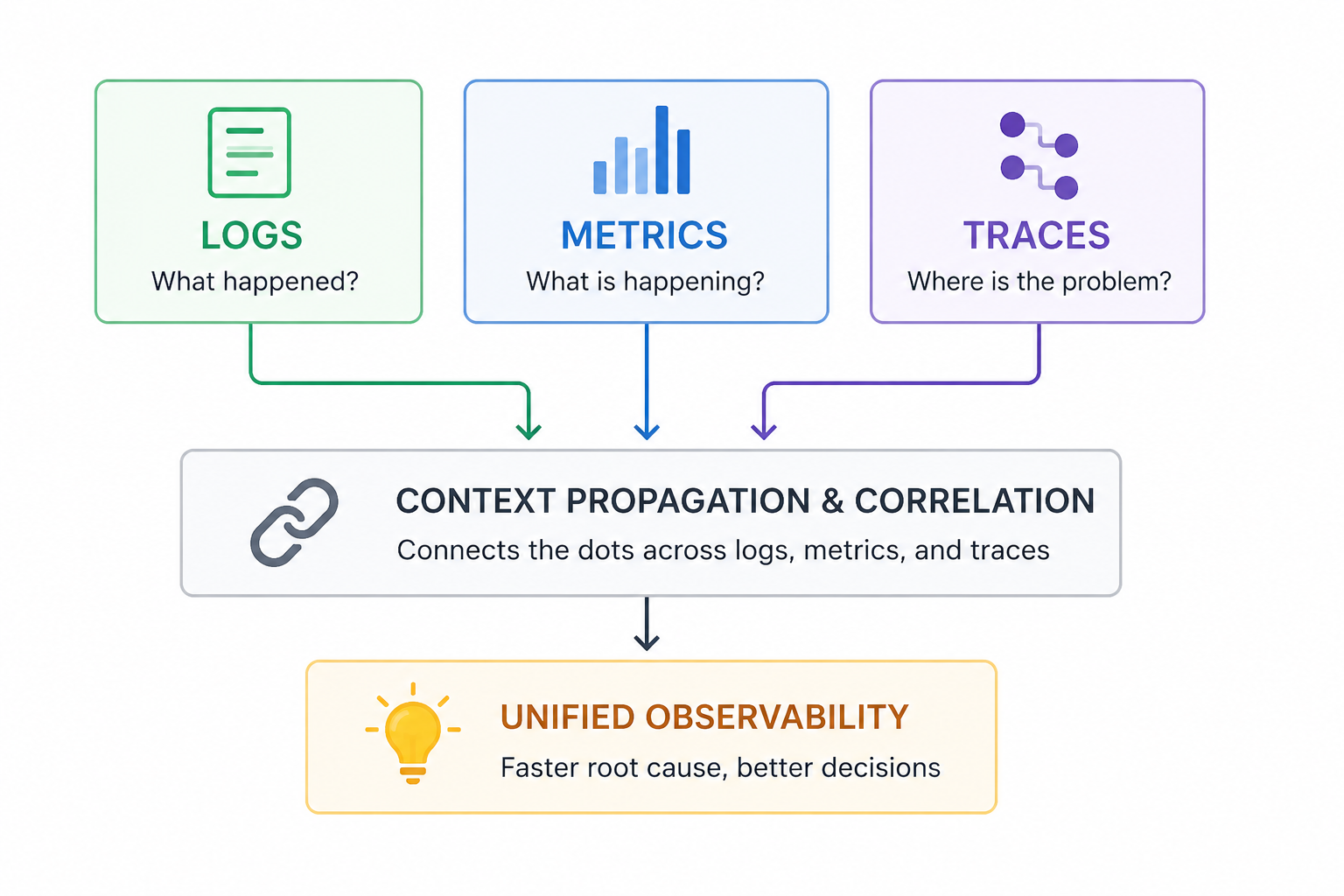
Observability hiện đại được xây dựng trên 3 thành phần cốt lõi:
- Logs: Ghi lại chi tiết sự kiện
- Metrics: Đo lường xu hướng & hiệu năng
- Traces: Theo dõi request xuyên suốt hệ thống
Tuy nhiên, Logs, Metrics và Traces sẽ không mang lại nhiều giá trị nếu chúng tồn tại tách biệt và thiếu sự liên kết về mặt ngữ cảnh.
Giá trị thực sự của Observability nằm ở khả năng Lan truyền và liên kết ngữ cảnh (Context Propagation & Correlation), cho phép kết nối toàn bộ dữ liệu đo lường hệ thống (telemetry data) thành một luồng quan sát thống nhất.
Nhờ đó, đội ngũ kỹ thuật có thể tái hiện và điều tra toàn bộ vòng đời của một request theo dạng end-to-end, từ frontend, backend cho đến database và external services.
3. Distributed Tracing Và W3C Trace Context
Trong các hệ thống phân tán, một request thường đi qua rất nhiều thành phần như:
- API Gateway
- Authentication Service
- Database
- Queue
- External APIs
Nếu không có cơ chế định danh thống nhất, việc điều tra root cause gần như trở thành “mò kim đáy bể”.
Để giải quyết bài toán này, các hệ thống hiện đại sử dụng chuẩn W3C Trace Context nhằm truyền định danh request giữa các services thông qua HTTP Headers.
Ví dụ một Trace Context:
traceparent: 00-0af7651916cd43dd8448eb211c80319c-b7ad6b7169203331-01
Trong đó:
- 00: Version của chuẩn W3C Trace Context
- 0af76519…: Trace ID — định danh duy nhất cho toàn bộ request xuyên suốt hệ thống
- b7ad6b71…: Span ID — định danh cho bước xử lý hiện tại
- 01: Trace Flags
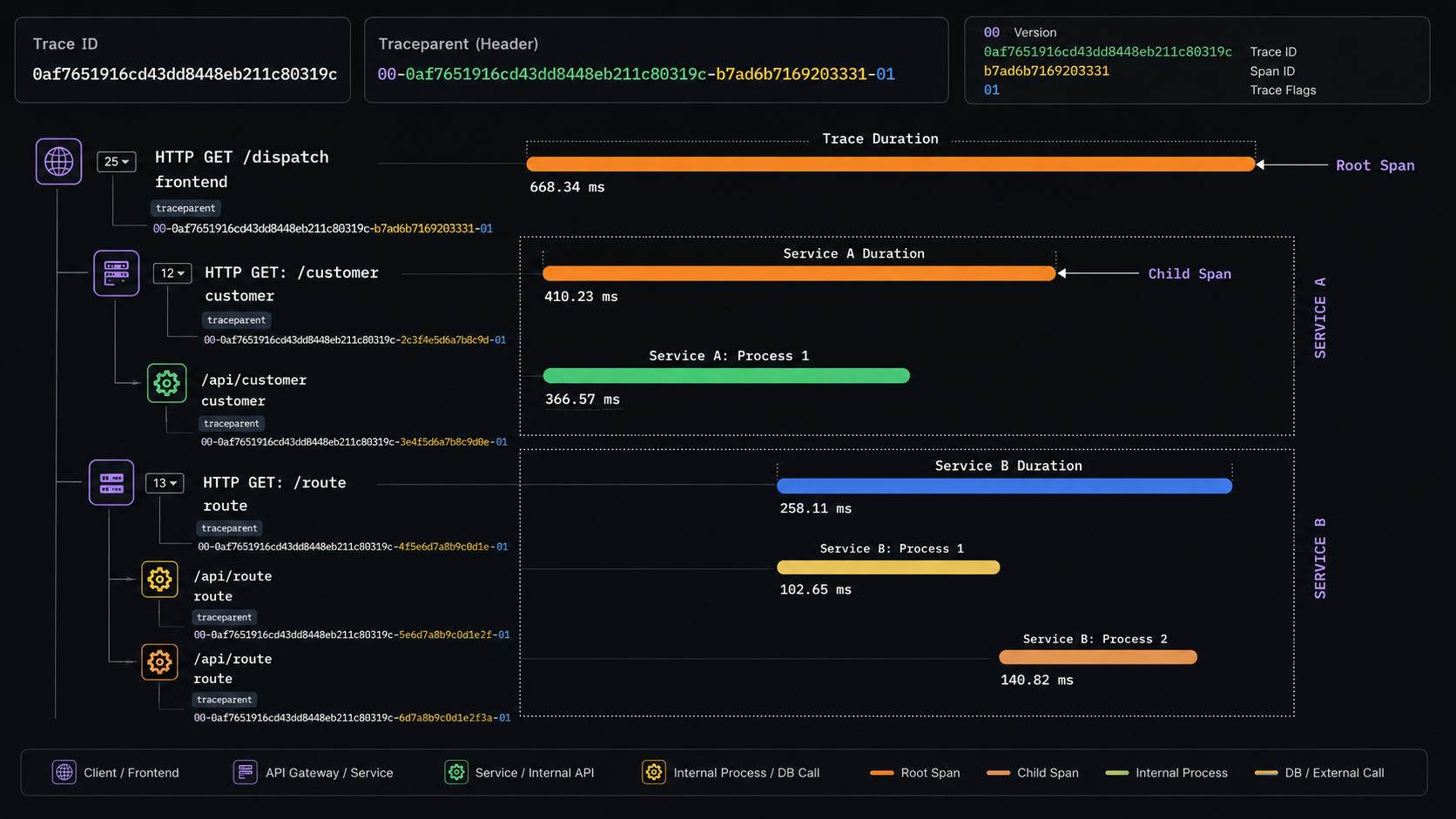
Khi request đi qua từng service:
- Trace ID sẽ tiếp tục được propagate sang downstream services
- Mỗi bước xử lý sẽ tạo ra một Span mới
- Hệ thống có thể tái hiện toàn bộ hành trình request end-to-end
Distributed Trace cho phép tái hiện toàn bộ hành trình của một request xuyên suốt hệ thống microservices theo thời gian thực, giúp xác định chính xác nơi phát sinh lỗi hoặc độ trễ trong hệ thống phân tán.
Chỉ cần một span bị chậm, toàn bộ trace sẽ cho thấy chính xác bottleneck đang nằm ở đâu.
4. Chuẩn Hóa Đo Lường: USE và RED
Một trong những nỗi ám ảnh lớn nhất của các kỹ sư SRE là Alert Fatigue (Nhiễu cảnh báo).
Việc thiết lập cảnh báo dựa trên nguyên nhân (Cause-based Alerting) — ví dụ như gửi cảnh báo khi “CPU Node > 80%” có thể khiến kỹ sư liên tục nhận notification cho những vấn đề hệ thống có khả năng tự phục hồi và chưa thực sự tác động đến người dùng.
Để giải quyết bài toán này, các tổ chức SRE hiện đại dần chuyển sang Symptom-based Alerting (Cảnh báo theo triệu chứng), tức tập trung vào những dấu hiệu ảnh hưởng trực tiếp đến trải nghiệm người dùng thay vì chỉ theo dõi trạng thái hạ tầng đơn thuần.
Cách tiếp cận này đòi hỏi sự tách biệt rõ ràng giữa các framework đo lường ở từng tầng kiến trúc nhằm phản ánh chính xác “sức khỏe” thực tế của hệ thống.
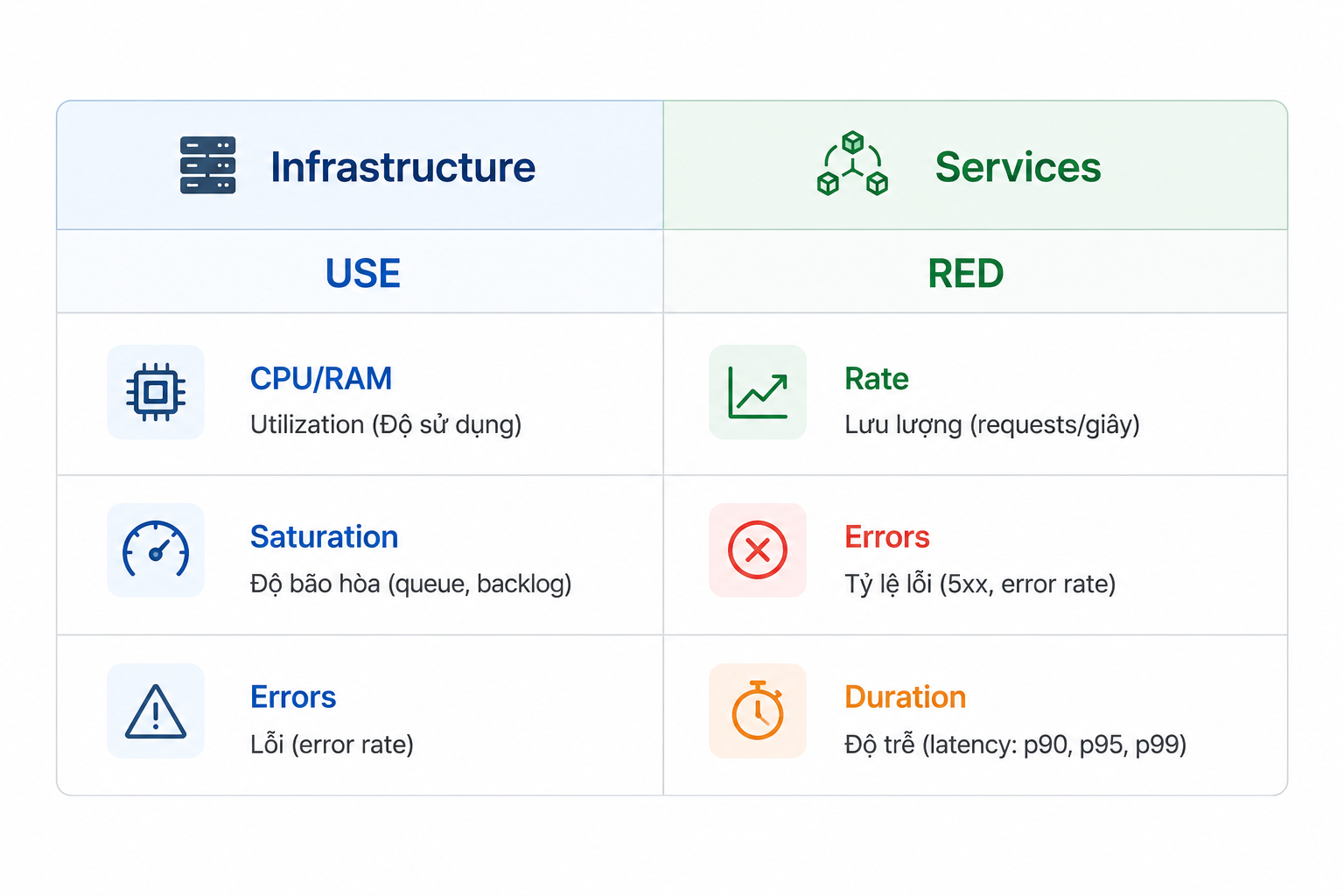
A. USE Method — Infrastructure Monitoring
Khi giám sát tài nguyên vật lý hoặc ảo hóa (CPU, Memory, Disk, Network), chúng ta sử dụng framework USE (Utilization, Saturation, Errors) của Brendan Gregg:
- Utilization (Độ sử dụng): Tỷ lệ % tài nguyên đang bận.
- Saturation (Độ bão hòa): Mức độ công việc đang phải xếp hàng chờ (Queue) do tài nguyên không kịp xử lý.
- Errors (Lỗi): Các sự kiện lỗi xảy ra trên tài nguyên đó.
B. RED Method — Service Monitoring
Khi đo lường dòng chảy dữ liệu qua các Microservices, trọng tâm dịch chuyển sang framework RED (Rate, Errors, Duration) của Tom Wilkie:
- Rate (Lưu lượng): Số lượng request mỗi giây (RPS).
- Errors (Lỗi): Tỷ lệ request thất bại (ví dụ: HTTP 5xx).
- Duration (Độ trễ): Thời gian hoàn thành request, thường được đo bằng các phân vị P90, P95, P99.
C. 4 Golden Signals & SLO
Bao trùm lên cả hai tầng trên là tiêu chuẩn 4 Tín hiệu Vàng (4 Golden Signals) được giới thiệu bởi Google SRE:
- Latency (Độ trễ)
- Traffic (Lưu lượng)
- Errors (Lỗi)
- Saturation (Độ bão hòa)
Từ các tín hiệu này, tổ chức sẽ xây dựng:
- SLI (Service Level Indicator – Chỉ số mức dịch vụ)
- SLO (Service Level Objective – Mục tiêu mức dịch vụ)
- Error Budget (Ngân sách lỗi)
Mục tiêu của SLO-based Alerting là:
- Giảm Alert Noise
- Tập trung vào Business Impact thực sự
Kỹ sư on-call sẽ không bị đánh thức vào lúc 3 giờ sáng chỉ vì một Node bị đầy RAM. Họ chỉ nhận cảnh báo mức độ Critical nếu SLO Burn Rate (Tốc độ đốt ngân sách lỗi) tăng vọt, đe dọa trực tiếp đến cam kết với khách hàng.
Bên cạnh đó, các công nghệ như:
- RUM (Real User Monitoring – Giám sát người dùng thực tế)
- APM (Application Performance Monitoring – Giám sát hiệu năng ứng dụng)
sẽ cung cấp góc nhìn xuyên suốt từ:
- Frontend
- Backend
- Database
- External services
trong cùng một luồng điều tra.
5. Telemetry Economics: Bài Toán Chi Phí và Khủng Hoảng Dữ Liệu
Mặt trái của Observability ở hệ thống High Traffic là chi phí lưu trữ và xử lý. Nếu không kiểm soát, hệ thống sẽ gặp phải bùng nổ chi phí (Cost Explosion).
- Actionable Telemetry thay vì “Data Hoarding”: Observability không đồng nghĩa với việc lưu toàn bộ dữ liệu. Thay vì lưu trữ toàn bộ raw logs, các hệ thống lớn sử dụng Log-to-Metric extraction để chuyển đổi log thành metric ngay tại tầng Ingestion, chỉ giữ lại raw logs khi thật sự cần thiết.
- Bùng nổ Cardinality (Cardinality Explosion): Việc gán các label có tính duy nhất cao (như user_id, session_id) vào Metrics sẽ tạo ra hàng triệu time-series, gây quá tải bộ nhớ RAM hoặc đội chi phí nền tảng SaaS lên nhiều lần. Đội ngũ cần có rule nghiêm ngặt về việc drop hoặc aggregate các high-cardinality labels.
- Chiến lược Sampling: Việc lưu trữ 100% traces thường không cần thiết. Các kiến trúc lớn áp dụng Head-based Sampling (lấy mẫu ngẫu nhiên ở đầu vào) hoặc tối ưu hơn là Tail-based Sampling (chỉ lưu lại Trace đầy đủ đối với những request bị lỗi hoặc vượt ngưỡng Latency cho phép).
6. Các Xu Hướng Định Hình Tương Lai
Hệ sinh thái Observability đang hội tụ về 3 xu hướng công nghệ lõi:
- Chuẩn hóa với OpenTelemetry (OTel): Ngành công nghiệp đang thống nhất sử dụng chuẩn OTLP. Nó giúp các tổ chức thu thập, xử lý dữ liệu mà không bị “Vendor Lock-in”, dễ dàng định tuyến telemetry data đến bất kỳ backend nào (Elastic, Grafana, SigNoz…) tùy thuộc vào bài toán chi phí.
- Sức mạnh của eBPF: Cho phép giám sát trực tiếp từ tầng Kernel của Linux với mức overhead cực kỳ thấp, mang lại khả năng Zero-code instrumentation, đặc biệt hữu ích cho Network và Security Observability.
- AI-Assisted Operations (AIOps): Machine Learning được ứng dụng vào việc giảm nhiễu hệ thống thông qua Log Clustering, Anomaly Detection, và Alert Correlation. Dù chưa thể thay thế Senior Engineer, AIOps thu hẹp đáng kể phạm vi điều tra và giảm MTTR (Mean Time To Recovery).
Kết Luận
Khi quy mô hệ thống ngày càng lớn, vấn đề không còn là: “Hệ thống có đang hoạt động hay không?” mà là: “Đội ngũ kỹ thuật có đủ khả năng quan sát để hiểu chính xác điều gì đang xảy ra bên trong hệ thống hay không?”
Khi hệ thống mở rộng sang Microservices và Cloud-Native, Observability không còn là một công cụ hỗ trợ mà là một phần của hạ tầng vận hành cốt lõi.
Một chiến lược Observability thành công là sự cân bằng giữa khả năng giám sát sâu sát (Deep Visibility) và chi phí vận hành (Telemetry Economics).
Triển khai đúng các tiêu chuẩn công nghiệp như USE, RED, OpenTelemetry, đồng thời quản lý tốt Cardinality và thiết lập các SLO cảnh báo thông minh không chỉ giúp bảo vệ SLA kinh doanh của tổ chức, mà còn đảm bảo một môi trường vận hành bền vững cho đội ngũ SRE.
 | Dương Nhật Hào Developer |
ỨNG TUYỂN
Chế độ phúc lợi






CÔNG VIỆC TƯƠNG TỰ





