Khám phá sức mạnh của Google Cloud Dataflow
Tổng quan về Google Cloud Dataflow
Định nghĩa và chức năng chính
Google Cloud Dataflow là một dịch vụ xử lý dữ liệu theo thời gian thực và theo lô hoàn toàn được quản lý trên nền tảng đám mây. Nó cho phép các nhà phát triển và doanh nghiệp xây dựng các pipeline xử lý dữ liệu có khả năng mở rộng và hiệu quả mà không cần quản lý cơ sở hạ tầng phức tạp.
Các chức năng chính của Google Cloud Dataflow bao gồm:
- Xử lý dữ liệu theo thời gian thực và theo lô.
- Tự động mở rộng và quản lý tài nguyên.
- Hỗ trợ nhiều ngôn ngữ lập trình như Java và Python.
- Tích hợp liền mạch với các dịch vụ Google Cloud khác.
So sánh với các giải pháp xử lý dữ liệu khác
| Tính năng | Google Cloud Dataflow | Apache Spark | Apache Flink |
| Mô hình xử lý | Thời gian thực và theo lô | Chủ yếu theo lô | Thời gian thực và theo lô |
| Quản lý | Hoàn toàn được quản lý | Tự quản lý | Tự quản lý |
| Khả năng mở rộng | Tự động | Thủ công | Thủ công |
| Ngôn ngữ hỗ trợ | Java, Python | Scala, Java, Python, R | Java, Scala |
| Tích hợp đám mây | Tích hợp sâu với GCP | Hỗ trợ nhiều nền tảng | Hỗ trợ nhiều nền tảng |
Lợi ích của việc sử dụng Dataflow
- Hiệu suất cao: Dataflow tự động tối ưu hóa pipeline xử lý dữ liệu để đạt hiệu suất tối đa.
- Tiết kiệm chi phí: Mô hình tính phí linh hoạt và khả năng tự động mở rộng giúp tiết kiệm chi phí vận hành.
- Dễ dàng phát triển: Mô hình lập trình đơn giản và thống nhất cho cả xử lý theo lô và thời gian thực.
- Khả năng mở rộng: Tự động mở rộng để đáp ứng nhu cầu xử lý dữ liệu tăng đột biến.
- Độ tin cậy cao: Hệ thống tự động xử lý lỗi và đảm bảo tính nhất quán của dữ liệu.
Với những ưu điểm này, Google Cloud Dataflow trở thành một lựa chọn hấp dẫn cho các doanh nghiệp muốn xây dựng hệ thống xử lý dữ liệu mạnh mẽ và linh hoạt trên nền tảng đám mây. Tiếp theo, chúng ta sẽ tìm hiểu về kiến trúc và các thành phần cốt lõi của Google Cloud Dataflow.
Kiến trúc và thành phần của Google Cloud Dataflow
Khả năng mở rộng và tính linh hoạt
Google Cloud Dataflow được thiết kế với khả năng mở rộng và tính linh hoạt cao, cho phép xử lý dữ liệu ở quy mô lớn một cách hiệu quả. Hệ thống tự động điều chỉnh tài nguyên dựa trên khối lượng công việc, đảm bảo hiệu suất tối ưu và tiết kiệm chi phí.
Tích hợp với các dịch vụ Google Cloud khác
Dataflow tích hợp mượt mà với nhiều dịch vụ Google Cloud khác, tạo nên một hệ sinh thái mạnh mẽ cho việc xử lý và phân tích dữ liệu. Dưới đây là bảng so sánh tích hợp của Dataflow với một số dịch vụ phổ biến:
| Dịch vụ Google Cloud | Tích hợp với Dataflow |
| BigQuery | Nhập/xuất dữ liệu trực tiếp |
| Cloud Storage | Lưu trữ dữ liệu đầu vào/đầu ra |
| Pub/Sub | Xử lý luồng dữ liệu thời gian thực |
| Cloud Spanner | Truy vấn và cập nhật cơ sở dữ liệu |
Các thành phần chính của Dataflow
Google Cloud Dataflow bao gồm các thành phần chính sau:
- Pipeline: Định nghĩa logic xử lý dữ liệu.
- PCollection: Đại diện cho tập dữ liệu đầu vào và đầu ra.
- Transform: Các phép biến đổi dữ liệu.
- Source và Sink: Xác định nguồn dữ liệu đầu vào và đích lưu trữ kết quả.
Mô hình xử lý dữ liệu
Dataflow hỗ trợ hai mô hình xử lý dữ liệu chính:
- Xử lý theo batch: Xử lý dữ liệu tĩnh theo lô.
- Xử lý streaming: Xử lý dữ liệu thời gian thực.
Với kiến trúc linh hoạt và các thành phần mạnh mẽ, Google Cloud Dataflow cung cấp nền tảng vững chắc cho việc xây dựng các pipeline xử lý dữ liệu phức tạp. Tiếp theo, chúng ta sẽ tìm hiểu về các tính năng nổi bật của Dataflow, giúp nó trở thành một công cụ không thể thiếu trong việc xử lý dữ liệu quy mô lớn.
Các tính năng nổi bật của Google Cloud Dataflow
Google Cloud Dataflow là một công cụ mạnh mẽ trong hệ sinh thái xử lý dữ liệu của Google Cloud. Hãy cùng khám phá những tính năng nổi bật làm nên sức mạnh của nó.
Mô hình lập trình thống nhất
Google Cloud Dataflow cung cấp một mô hình lập trình thống nhất cho cả xử lý dữ liệu theo batch và theo thời gian thực. Điều này cho phép các nhà phát triển sử dụng cùng một mã nguồn cho cả hai loại xử lý, giúp tiết kiệm thời gian và công sức trong việc phát triển và bảo trì.
Khả năng xử lý dữ liệu đa dạng
Dataflow có khả năng xử lý nhiều loại dữ liệu khác nhau, từ dữ liệu có cấu trúc đến dữ liệu phi cấu trúc. Nó hỗ trợ các nguồn dữ liệu đa dạng như:
- Cơ sở dữ liệu quan hệ.
- NoSQL databases.
- Hệ thống tệp.
- Dữ liệu từ các API.
Tự động tối ưu hóa pipeline
Một trong những tính năng ấn tượng nhất của Dataflow là khả năng tự động tối ưu hóa pipeline. Hệ thống sẽ:
- Phân tích luồng dữ liệu.
- Xác định các điểm nghẽn.
- Tự động điều chỉnh tài nguyên.
Điều này giúp đảm bảo hiệu suất tối ưu mà không cần can thiệp thủ công từ người dùng.
Xử lý dữ liệu theo batch
Dataflow cung cấp khả năng xử lý dữ liệu theo batch mạnh mẽ, cho phép xử lý lượng lớn dữ liệu tĩnh một cách hiệu quả. Nó hỗ trợ các tác vụ như:
- Phân tích dữ liệu lịch sử.
- Tạo báo cáo định kỳ.
- Xử lý dữ liệu hàng loạt.
Xử lý dữ liệu theo thời gian thực
Cuối cùng, Dataflow cũng xuất sắc trong việc xử lý dữ liệu theo thời gian thực. Nó cho phép:
| Tính năng | Mô tả |
| Xử lý luồng | Xử lý dữ liệu liên tục khi nó được tạo ra |
| Phân tích thời gian thực | Cung cấp thông tin chi tiết ngay lập tức |
| Phản ứng nhanh | Cho phép ra quyết định dựa trên dữ liệu mới nhất |
Với những tính năng mạnh mẽ này, Google Cloud Dataflow đã trở thành một công cụ không thể thiếu trong việc xử lý dữ liệu quy mô lớn. Tiếp theo, chúng ta sẽ khám phá các ứng dụng thực tế của Dataflow trong các ngành công nghiệp khác nhau.
Ứng dụng thực tế của Google Cloud Dataflow
Google Cloud Dataflow đã chứng minh sự linh hoạt và hiệu quả của mình trong nhiều lĩnh vực ứng dụng thực tế. Hãy cùng khám phá một số ứng dụng nổi bật của công cụ mạnh mẽ này.
A. Xây dựng hệ thống Machine Learning và Trí tuệ nhân tạo
Google Cloud Dataflow đóng vai trò quan trọng trong việc xây dựng và triển khai các hệ thống Machine Learning (ML) và Trí tuệ nhân tạo (AI). Nó cung cấp khả năng xử lý dữ liệu quy mô lớn, giúp các nhà phát triển:
- Tiền xử lý và làm sạch dữ liệu đầu vào.
- Trích xuất và chuyển đổi đặc trưng.
- Huấn luyện và đánh giá mô hình ML/AI.
| Ưu điểm | Mô tả |
| Tích hợp seamless | Kết nối dễ dàng với các dịch vụ ML/AI của Google Cloud |
| Xử lý theo batch và streaming | Hỗ trợ cả xử lý dữ liệu theo lô và theo thời gian thực |
| Khả năng mở rộng | Tự động điều chỉnh tài nguyên để đáp ứng khối lượng công việc |
B. Tích hợp và chuyển đổi dữ liệu
Dataflow là công cụ mạnh mẽ cho việc tích hợp và chuyển đổi dữ liệu từ nhiều nguồn khác nhau. Các ứng dụng phổ biến bao gồm:
- ETL (Extract, Transform, Load) quy mô lớn.
- Đồng bộ hóa dữ liệu giữa các hệ thống.
- Chuẩn hóa và làm sạch dữ liệu.
C. Xử lý dữ liệu IoT
Trong lĩnh vực Internet of Things (IoT), Dataflow đóng vai trò then chốt trong việc xử lý lượng lớn dữ liệu từ các thiết bị cảm biến. Nó cho phép:
- Xử lý dữ liệu theo thời gian thực từ hàng triệu thiết bị.
- Phát hiện anomaly và cảnh báo.
- Tổng hợp và phân tích dữ liệu IoT.
D. Phân tích dữ liệu lớn
Cuối cùng, Dataflow là công cụ lý tưởng cho phân tích dữ liệu lớn, cung cấp:
- Khả năng xử lý petabyte dữ liệu.
- Tính toán phân tán hiệu quả.
- Tích hợp với các công cụ phân tích và trực quan hóa dữ liệu.
Với những ứng dụng đa dạng này, Google Cloud Dataflow đã trở thành công cụ không thể thiếu đối với nhiều doanh nghiệp trong việc khai thác sức mạnh của dữ liệu. Tiếp theo, chúng ta sẽ tìm hiểu cách bắt đầu sử dụng Google Cloud Dataflow để áp dụng vào các dự án của riêng bạn.
Bắt đầu với Google Cloud Dataflow
A. Tài liệu
Google Cloud Dataflow cung cấp một loạt tài liệu và tài nguyên học tập phong phú để giúp bạn bắt đầu. Trang chủ chính thức của Google Cloud Dataflow là điểm khởi đầu tuyệt vời, cung cấp tổng quan, hướng dẫn và tài liệu tham khảo API. Ngoài ra, Google cũng cung cấp các khóa học trực tuyến miễn phí và có chứng chỉ thông qua Google Cloud Training.
https://cloud.google.com/dataflow/docs/overview
B. Các công cụ và SDK hỗ trợ
Google Cloud Dataflow hỗ trợ nhiều công cụ và SDK để phát triển pipeline:
- Apache Beam SDK: Hỗ trợ Java, Python và Go.
- Google Cloud Console: Giao diện web để quản lý và giám sát các job Dataflow.
- Google Cloud SDK: Công cụ dòng lệnh để tương tác với Dataflow.
| Công cụ | Ngôn ngữ hỗ trợ | Mục đích sử dụng |
| Apache Beam SDK | Java, Python, Go | Phát triển pipeline |
| Google Cloud Console | Web interface | Quản lý và giám sát |
| Google Cloud SDK | Command-line | Tương tác với Dataflow |
C. Tạo và chạy pipeline đầu tiên
Để tạo và chạy pipeline đầu tiên, bạn cần thực hiện các bước sau:
- Cài đặt Apache Beam SDK.
- Viết mã pipeline sử dụng Beam SDK.
- Cấu hình các tham số Dataflow.
- Chạy pipeline trên Google Cloud Dataflow.
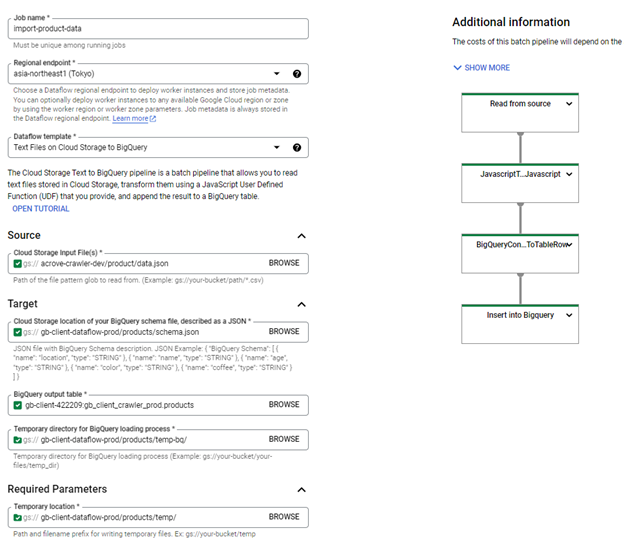
D. Triển khai dataflow Job (Import GCS data vào BigQuery)
- Sử dụng template có sẵn của Google (Text Files on Cloud Storage to Big Query).
- Truy cập vào GCP Dataflow console.
- Fill các thông tin vào form tạo Dataflow jobs.
| Thuộc tính | Giá trị | Giải thích |
| Job name | import-product-data | Tên dataflow job |
| Regional endpoint: | asia-northeast1 (Tokyo) | Dataflow region |
| Dataflow Template | Text Files on Cloud Storage to Big Query | Template cho phép đọc các tệp văn bản được lưu trữ trong Cloud Storage, chuyển đổi chúng bằng Hàm do người dùng xác định JavaScript (UDF) do bạn cung cấp và thêm kết quả vào bảng BigQuery. |
| Cloud Storage Input File Pattern | gs://{data_bucket_name}/sample-data/*.jsonl | Data file format |
| Cloud Storage location of BQ schema | gs://{dataflow_bucket_name}/products/schema.json | Bigquery schema json file |
| BQ output table | {PROJECT_ID}:{dataset}.{table} | Bigquery table |
| Temp directory for BQ loading process | gs://{dataflow_bucket_name}/products/temp-bq/ | Thư mục tạm thời cho quá trình load data vào Bigquery |
| Temp location | gs://{dataflow_bucket_name}/products/temp/ | Đường dẫn và tiền tố tên tệp để ghi tệp tạm thời |
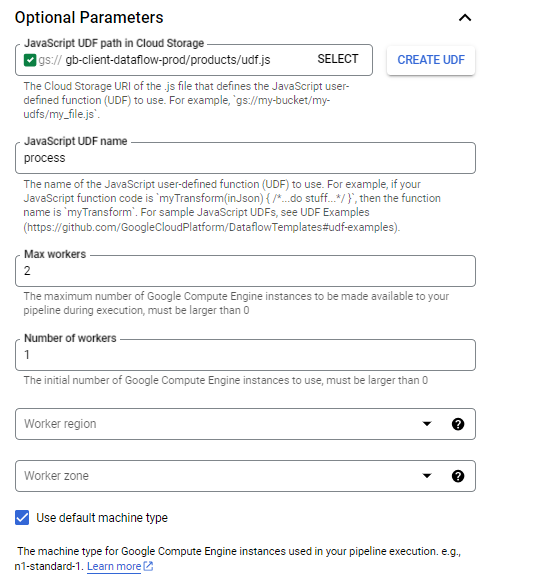
| Javascript UDF path in Cloud Storage | gs://{dataflow_bucket_name}/products/udf.js | URI lưu trữ đám mây của tệp .js xác định hàm do người dùng xác định (UDF) JavaScript |
| Javascript UDF name | process | Tên của hàm do người dùng định nghĩa JavaScript (UDF) |
| Max workers | 2 | Số lượng tối đa các phiên bản Google Compute Engine có thể sử dụng cho pipeline trong quá trình thực thi (phải lớn hơn 0) |
| Number of workers | 1 | Số lượng phiên bản Google Compute Engine ban đầu được sử dụng (phải lớn hơn 0) |
Ví dụ bạn có jsonl data file (gs://{data_bucket_name}/sample-data/data.jsonl) với format như sau:
{“name”: “Nguyễn A”, “age”: “20”} {“name”: “Trần B”, “age”: “25”}
Dưới đây sẽ là config code cho dataflow job:
1. Bigquery schema file (gs://{dataflow_bucket_name}/products/schema.json)
{ “BigQuery Schema”: [ { “name”: “name”, “type”: “STRING” }, { “name”: “age”, “type”: “INTEGER” }, ] }
2. UDF function
{ function process(inJson) { val = inJson.split(“,”); const obj = { “name”: val[0], “age”: parseInt(val[1]) }; return JSON.stringify(obj); } }
Sau đó nhấn nút “Run job”.
Dataflow job sẽ được khởi chạy, tiến trình của job sẽ được hiển thị thông qua màn hình job detail:
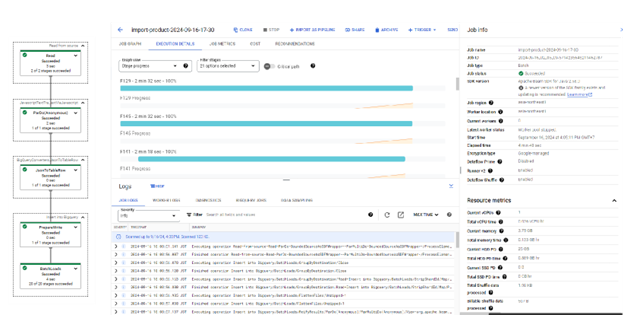
Sau khi tất cả các tiến trình chạy thành công, chúng ta có thể check data trong Bigquery table.
Tổng kết
Google Cloud Dataflow là một công cụ mạnh mẽ cho việc xử lý dữ liệu quy mô lớn, cung cấp khả năng xử lý dữ liệu theo thời gian thực và theo lô. Với kiến trúc linh hoạt và các tính năng nổi bật như mô hình lập trình thống nhất, tự động tối ưu hóa và khả năng mở rộng tự động, Dataflow đáp ứng được nhiều nhu cầu xử lý dữ liệu phức tạp trong các ứng dụng thực tế.
Bằng cách tận dụng sức mạnh của Google Cloud Dataflow, các doanh nghiệp và nhà phát triển có thể tập trung vào việc xây dựng các giải pháp dữ liệu sáng tạo mà không phải lo lắng về cơ sở hạ tầng. Với môi trường phát triển được thiết lập đúng cách, bạn có thể bắt đầu phát triển và triển khai các pipeline Dataflow một cách hiệu quả. Hãy bắt đầu khám phá Google Cloud Dataflow ngay hôm nay để mở ra tiềm năng xử lý dữ liệu mạnh mẽ cho dự án của bạn.
 | Nguyễn Xuân Việt Anh Developer |
ỨNG TUYỂN
Chế độ phúc lợi






CÔNG VIỆC TƯƠNG TỰ





