Exploring the Power of Google Cloud Dataflow
Overview of Google Cloud Dataflow
Definition and Key Features
Google Cloud Dataflow is a fully managed real-time and batch data processing service on the cloud platform. It enables developers and businesses to build scalable and efficient data processing pipelines without having to manage complex infrastructure.
The key features of Google Cloud Dataflow include:
- Real-time and batch data processing.
- Automatic scaling and resource management.
- Support for multiple programming languages like Java and Python.
- Seamless integration with other Google Cloud services.
Comparison with Other Data Processing Solutions
| Feature | Google Cloud Dataflow | Apache Spark | Apache Flink |
| Processing Model | Real-time and batch | Mainly batch | Real-time and batch |
| Management | Fully managed | Self-managed | Self-managed |
| Scalability | Automatic | Manual | Manual |
| Supported Languages | Java, Python | Scala, Java, Python, R | Java, Scala |
| Cloud Integration | Deep integration with GCP | Supports multiple platforms | Supports multiple platforms |
Benefits of Using Dataflow
- High performance: Dataflow automatically optimizes data processing pipelines for maximum efficiency.
- Cost savings: The flexible pricing model and automatic scaling help reduce operational costs.
- Ease of development: A simple, unified programming model for both batch and real-time processing.
- Scalability: Automatically scales to handle sudden increases in data processing demand.
- High reliability: The system automatically handles errors and ensures data consistency.
With these advantages, Google Cloud Dataflow becomes an attractive option for businesses looking to build powerful and flexible data processing systems on the cloud. Next, let’s explore the architecture and core components of Google Cloud Dataflow.
Architecture and Components of Google Cloud Dataflow
Scalability and Flexibility
Google Cloud Dataflow is designed for high scalability and flexibility, allowing efficient data processing at a large scale. The system automatically adjusts resources based on workload, ensuring optimal performance and cost savings.
Integration with Other Google Cloud Services
Dataflow integrates seamlessly with many other Google Cloud services, creating a powerful ecosystem for data processing and analytics. Below is a comparison of Dataflow integration with some popular services:
| Google Cloud Service | Integration with Dataflow |
| BigQuery | Direct data import/export |
| Cloud Storage | Data storage for input/output |
| Pub/Sub | Real-time data stream processing |
| Cloud Spanner | Querying and updating databases |
Core Components of Dataflow
Google Cloud Dataflow includes the following key components:
- Pipeline: Defines the data processing logic.
- PCollection: Represents the input and output data sets.
- Transform: Data transformation operations.
- Source and Sink: Defines data input sources and result storage destinations.
Data Processing Models
Dataflow supports two main data processing models:
- Batch processing: Processes static data in batches.
- Streaming processing: Processes real-time data.
With its flexible architecture and powerful components, Google Cloud Dataflow provides a solid foundation for building complex data processing pipelines. Next, we will explore Dataflow’s outstanding features, which make it an essential tool for large-scale data processing.
Outstanding Features of Google Cloud Dataflow
Google Cloud Dataflow is a powerful tool in the Google Cloud data processing ecosystem. Let’s explore the outstanding features that make it so powerful.
Unified Programming Model
Google Cloud Dataflow provides a unified programming model for both batch and real-time data processing. This allows developers to use the same codebase for both types of processing, saving time and effort in development and maintenance.
Diverse Data Processing Capabilities
Dataflow can process many types of data, from structured to unstructured data. It supports various data sources such as:
- Relational databases.
- NoSQL databases.
- File systems.
- Data from APIs.
Automatic Pipeline Optimization
One of Dataflow’s most impressive features is its ability to automatically optimize pipelines. The system will:
- Analyze data streams.
- Identify bottlenecks.
- Automatically adjust resources.
This ensures optimal performance without manual intervention from the user.
Batch Data Processing
Dataflow provides powerful batch data processing capabilities, allowing for efficient processing of large volumes of static data. It supports tasks such as:
- Historical data analysis.
- Periodic reporting.
- Batch data processing.
Real-time Data Processing
Finally, Dataflow excels in real-time data processing. It enables:
| Feature | Description |
| Stream processing | Continuously processes data as it is generated |
| Real-time analytics | Provides instant insights |
| Quick response | Enables decision-making based on the most recent data |
With these powerful features, Google Cloud Dataflow has become an indispensable tool for large-scale data processing. Next, we will explore real-world applications of Dataflow across various industries.
Real-World Applications of Google Cloud Dataflow
Google Cloud Dataflow has demonstrated its flexibility and efficiency in many real-world applications. Let’s explore some of its most notable uses.
A. Building Machine Learning and Artificial Intelligence Systems
Google Cloud Dataflow plays a crucial role in building and deploying Machine Learning (ML) and Artificial Intelligence (AI) systems. It provides the ability to process large-scale data, helping developers:
- Preprocess and clean input data.
- Extract and transform features.
- Train and evaluate ML/AI models.
| Advantage | Description |
| Seamless integration | Easy connection to Google Cloud ML/AI services |
| Batch and streaming processing | Supports both batch and real-time data processing |
| Scalability | Automatically adjusts resources to handle workload |
B. Data Integration and Transformation
Dataflow is a powerful tool for integrating and transforming data from multiple sources. Common applications include:
- Large-scale ETL (Extract, Transform, Load).
- Data synchronization between systems.
- Data normalization and cleansing.
C. IoT Data Processing
In the Internet of Things (IoT) space, Dataflow plays a key role in processing massive amounts of data from sensor devices. It allows:
- Real-time processing of data from millions of devices.
- Detection of anomalies and alerts.
- Aggregation and analysis of IoT data.
D. Big Data Analytics
Finally, Dataflow is ideal for big data analytics, providing:
- Ability to process petabytes of data.
- Efficient distributed computing.
- Integration with data analytics and visualization tools.
With these diverse applications, Google Cloud Dataflow has become an indispensable tool for many businesses in harnessing the power of data. Next, we will learn how to get started with Google Cloud Dataflow for your own projects.
Getting Started with Google Cloud Dataflow
A. Documentation
Google Cloud Dataflow provides a wealth of documentation and learning resources to help you get started. The official Google Cloud Dataflow homepage is a great starting point, offering overviews, guides, and API reference materials. Additionally, Google provides free online courses with certifications through Google Cloud Training.
https://cloud.google.com/dataflow/docs/overview
B. Supported Tools and SDKs
Google Cloud Dataflow supports many tools and SDKs for developing pipelines:
- Apache Beam SDK: Supports Java, Python, and Go.
- Google Cloud Console: Web interface for managing and monitoring Dataflow jobs.
- Google Cloud SDK: Command-line tool for interacting with Dataflow.
| Tool | Supported Languages | Purpose |
| Apache Beam SDK | Java, Python, Go | Pipeline development |
| Google Cloud Console | Web interface | Managing and monitoring |
| Google Cloud SDK | Command-line | Interacting with Dataflow |
C. Create and Run Your First Pipeline
To create and run your first pipeline, follow these steps:
- Install the Apache Beam SDK.
- Write your pipeline code using the Beam SDK.
- Configure Dataflow parameters.
- Run the pipeline on Google Cloud Dataflow.
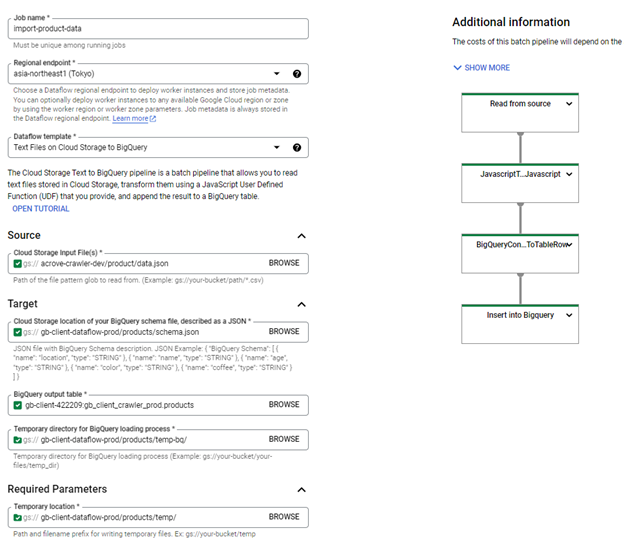
D. Deploy Dataflow Job (Import GCS Data to BigQuery)
- Use the built-in template from Google (Text Files on Cloud Storage to BigQuery).
- Access the GCP Dataflow console.
- Fill out the form to create Dataflow jobs.
| Property | Value | Description |
| Job name | import-product-data | Dataflow job name |
| Regional endpoint: | asia-northeast1 (Tokyo) | Dataflow region |
| Dataflow Template | Text Files on Cloud Storage to Big Query | Template that reads text files from Cloud Storage, transforms them with a user-defined JavaScript function (UDF) you provide, and inserts the result into a BigQuery table. |
| Cloud Storage Input File Pattern | gs://{data_bucket_name}/sample-data/*.jsonl | Data file format |
| Cloud Storage location of BQ schema | gs://{dataflow_bucket_name}/products/schema.json | BigQuery schema JSON file |
| BQ output table | {PROJECT_ID}:{dataset}.{table} | BigQuery table |
| Temp directory for BQ loading process | gs://{dataflow_bucket_name}/products/temp-bq/ | Temporary directory for loading data into BigQuery |
| Temp location | gs://{dataflow_bucket_name}/products/temp/ | Path and file name prefix for temporary files |
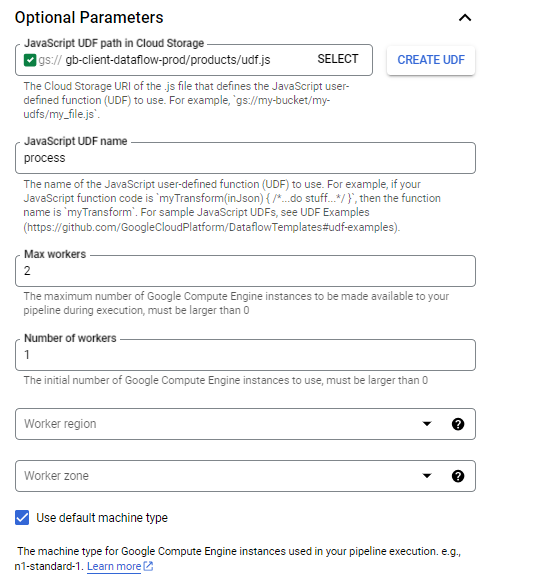
| Javascript UDF path in Cloud Storage | gs://{dataflow_bucket_name}/products/udf.js | Cloud Storage URI for the JavaScript file containing the user-defined function (UDF) |
| Javascript UDF name | process | Name of the user-defined JavaScript function (UDF) |
| Max workers | 2 | Maximum number of Google Compute Engine instances that can be used for the pipeline during execution (must be greater than 0) |
| Number of workers | 1 | Initial number of Google Compute Engine instances used (must be greater than 0) |
For example, you have a jsonl data file (gs://{data_bucket_name}/sample-data/data.jsonl) with the following format:
{“name”: “Nguyễn A”, “age”: “20”} {“name”: “Trần B”, “age”: “25”}
Below is the config code for the Dataflow job:
1. BigQuery schema file (gs://{dataflow_bucket_name}/products/schema.json)
{ “BigQuery Schema”: [ { “name”: “name”, “type”: “STRING” }, { “name”: “age”, “type”: “INTEGER” }, ] }
2. UDF function
{ function process(inJson) { val = inJson.split(“,”); const obj = { “name”: val[0], “age”: parseInt(val[1]) }; return JSON.stringify(obj); } }
Then click “Run job”.
The Dataflow job will start, and the job progress will be displayed in the job details screen:
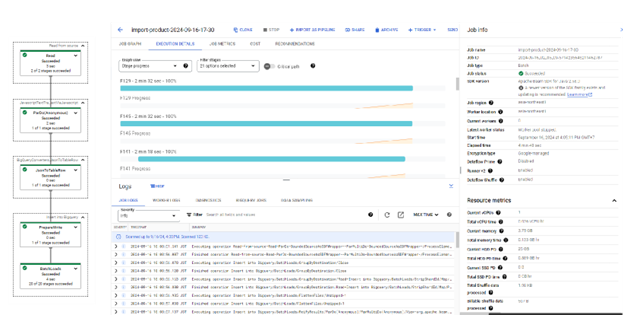
After all processes run successfully, we can check the data in the BigQuery table.
Conclusion
Google Cloud Dataflow is a powerful tool for large-scale data processing, offering real-time and batch data processing capabilities. With its flexible architecture and features like unified programming model, automatic optimization, and auto-scaling, Dataflow can handle complex data processing needs in real-world applications.
By leveraging the power of Google Cloud Dataflow, businesses and developers can focus on building innovative data solutions without worrying about infrastructure. With the right setup, you can start developing and deploying Dataflow pipelines efficiently. Start exploring Google Cloud Dataflow today to unlock powerful data processing potential for your project.
 | Nguyễn Xuân Việt Anh Developer |
APPLY NOW
Benefits

RiverCrane Vietnam sympathizes staffs' innermost feelings and desires and set up termly salary review policy. Performance evaluation is conducted in June and December and salary change is conducted in January and July every year. Besides, outstanding staffs receive bonus for their achievements periodically (monthly, yearly).



Activities such as Team Building, Company Building, Family Building, Summer Holiday, Mid-Autum Festival, etc. will be the moments worthy of remembrance for each individual in the project or the pride when one introduces the company to his or her family, and shares the message "We are One".




