//Blog
AI – 超能力と秘密兵器

Chào 500 anh em coder! Hãy cùng nhau khám phá một chủ đề đang làm mưa làm gió: Trí tuệ nhân tạo (AI). Tương lai của lập trình có nằm trong tay trí tuệ nhân tạo?
もっと見る- 82 ビュー
- 0 コメント
Vector databaseとは? AIデータ技術の探求
現在のビッグデータ時代において、従来のデータベースでは非構造化データ(テキスト、画像、動画など)から情報を取得し、解析することに限界があります。これらのデータを検索する方法は、計算負荷が高く、構造と保存方法の制約により、期待する効率が得られません。そこで登場したのが、Vector databaseです。これがどのように機能するのかを一緒に見ていきましょう。 1. 概念とコア技術 Vector databaseは、「vector embeddings」(データを数値に変換して意味や関係を抽出する方法)を格納・管理するために設計されたデータベースです。 従来の関係データベースがデータをテーブル内の行と列に格納するのに対して、vector databaseは「vector embeddings」を利用してデータをベクトルとして格納します。Embeddingsは、データの特徴を多次元空間におけるベクトルとして表現したもので、類似性や関連性のある属性は空間的に近い位置に格納されます。 (出典: Pinecone) これにより、機械学習モデルや高度な検索アルゴリズムが、正確な一致ではなく、コンテンツの類似性に基づいてクエリ項目の類似点や違いを評価することが可能になります。これが、画像検索やレコメンドシステムなど、AIアプリケーションにとって重要な利点となります。 (出典: Weaviate) Googleの資料には次のように書かれています: “未来には、すべてのデータベースがベクトルデータベースになるだろう.” 2. ベクトルデータベースの利点と実際の応用 ソーシャルメディアやIoT(Internet of Things)デバイスなど、ますます多くのデータが生成される中で、ベクトルデータベースのスケーラビリティは、大規模データの分析・処理における理想的な解決策となります。 ベクトルデータベースは、高速で正確なクエリを提供し、特に大規模で非構造化データの処理において優れた性能を発揮します。これにより、意味論的検索、レコメンドシステム、画像認識など、迅速なデータ検索が求められるアプリケーションに最適なツールとなります。 ベクトルデータベースの代表的な利用例は、オンラインショッピングプラットフォームでの視覚的検索です。例えば、顧客が購入したい商品を画像でアップロードすると、システムはベクトルデータベースを使用して、その画像と類似した商品を正確に検索し、提案します。これは、アップロードされた画像と商品の画像がデータベース内のベクトルで比較されることで実現されます。 3. 使用されるツールと技術 ベクトルデータベースには、Pinecone、Faiss、Milvusなど、さまざまなツールがあります。これらのツールはそれぞれ異なる特長を持ち、特定のアプリケーションのニーズに合わせて適切に選ばれます。 初心者の方には、MilvusやPineconeなどのソフトウェアを選び、サーバーやクラウド環境にインストールし、ベクトル形式に変換したデータをデータベースにインポートして、類似性検索やその他の分析クエリを実行する手順を学ぶことから始めると良いでしょう。 また、最近ではGoogleのAlloyDB AIが、ベクトルデータの保存とクエリ速度の面で非常に優れたサポートを提供しています。 (出典: Google) GoogleのAlloyDBを使用することは、大規模データの管理と分析に有効なソリューションです。私はGoogle Cloud Platform(GCP)でインスタンスを立ち上げ、製品レビューのデータを処理・分析した経験があります。インスタンスを設定した後、製品レビューのデータをインポートしました。さらに、このレビューをベクトル形式に変換するために「textembedding-gecko」というテキスト埋め込みモデルを使用しました。 これにより、クエリがより正確で効率的になり、顧客の製品に対する感想やフィードバックを深く分析することができ、より賢明なビジネス判断をサポートします。 4. 結論 コンピュータ技術とAIの進歩は、データ分析や検索の可能性を広げ続けています。その中で、ベクトルデータベースは多くの企業にとってデータインフラの不可欠な要素となり、より高速で正確な検索と分析を実現する未来を約束しています。 この記事がベクトルデータベースについての概要を提供し、なぜそれがテクノロジー業界でますます注目されているのかを理解する助けになることを願っています。 Biện Hoàng ThyPHP Developer
もっと見る- 268 ビュー
- 0 コメント
gRPC – マイクロサービスのための新たな一歩
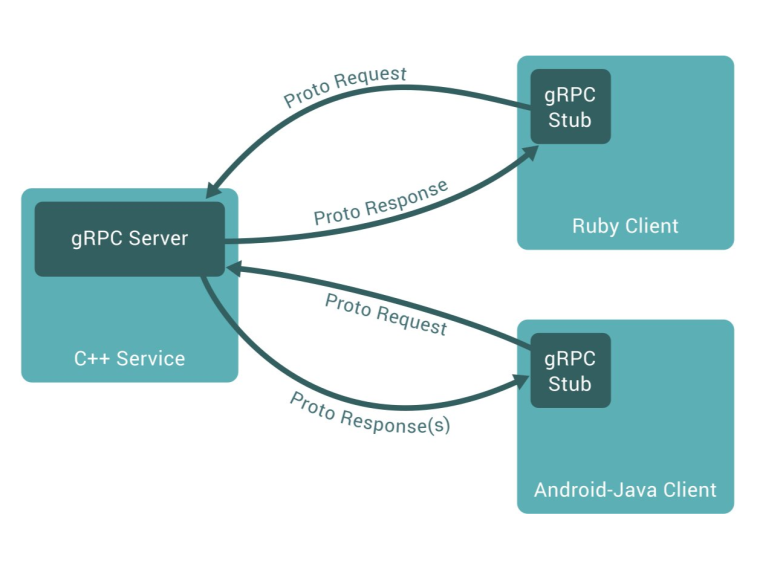
システムがマイクロサービスアーキテクチャに移行する際、APIの呼び出しが増え、その結果、データ転送の負荷によりパフォーマンスが低下することがあります。gRPCは、この問題に対する有力な解決策として登場しました。 この記事では、gRPCの基本的な概念と動作理論を提供し、その動作方法、利点、欠点、将来の適用可能性について理解できるようにします。 1. gRPCの紹介 gRPCは、分散システム内でサービス間の効率的なリモートプロシージャコール(RPC)をサポートするオープンソースのフレームワークです。 このプラットフォームはGoogleによって開発され、データ転送にHTTP/2プロトコルを使用することで、従来のRESTful APIと比較して優れた利点を提供します。 gRPCを使用すると、ローカルマシンでの関数呼び出しのようにコードを書けるため、実際には別のマシン上にある関数を呼び出していることになります。 2. gRPCの動作方式 gRPCは、protobufを使用してサービスやメソッドを遠隔で呼び出すために定義します。 gRPCのウェブサイトからの画像 Protobuf(Protocol Buffers)はIDL(Interface Definition Language)であり、通信インターフェースの定義言語で、データ構造を記述するために使用されます。 私たちは.protoファイルでサービスのメソッドとデータ構造を定義し、その後、protocを使って他のプログラミング言語に変換し、これらのデータ構造をバイナリストリームにシリアライズおよびデシリアライズします。 XMLやJSONの形式と比較して、生成されるデータは3~10倍小さく、非常に高速に処理されます。 gRPCアーキテクチャ gRPCは、サービス定義からサーバーとクライアント用のスタブコードを生成するツールを提供します。 クライアントはスタブを使ってサーバー上のメソッドを呼び出し、サーバーとクライアント間でデータはバイナリ形式で送信されます。 3. gRPCの利点 高パフォーマンス: gRPCはprotobufを使用してバイナリデータをエンコードするため、JSONやXMLよりもデータの転送サイズを減らし、処理速度を向上させます。 ProtobufはJSONよりも速度とサイズで優れています。詳細はこちらをご覧ください。 リソースの節約: gRPCはHTTP/2を使用しており、CPUやメモリの負荷を減らし、1つの接続で複数のリクエスト/レスポンスを送信できます。 多言語サポート: gRPCはJava、Python、Go、C++、PHP、Rubyなどの主要なプログラミング言語をサポートしており、異なる言語で書かれたアプリケーション間での通信が可能です。 柔軟性: gRPCはMicroservicesからIoT、ストリーミングメディアまで、さまざまなユースケースで使用できます。 クロスプラットフォームサポート: gRPCは多くのOSやアーキテクチャで動作するため、システムの互換性が向上します。 セキュリティ: gRPCはTLS/SSLといったセキュリティプロトコルをサポートしており、データ転送の保護を提供します。 効率的な接続管理: gRPCはHTTP/2のマルチプレクシングなど、効率的な接続管理機能を提供し、接続の数を減らしてパフォーマンスを向上させます。 スケーラビリティ: gRPCは、大規模な接続数や高いトラフィック処理に対応できるように簡単にスケーリングできます。 4. gRPCの欠点 学習曲線が高い: gRPCはprotobufを使用するため、その理解には一定の学習が必要です。これにより、RESTful APIと比較して学習が難しくなる場合があります。 RESTful APIほど広くないサポートコミュニティ: RESTful APIは長年使用されており、サポートコミュニティが広く強力ですが、gRPCはそれに比べるとサポートがまだ少ない場合があります。 デバッグが難しい: gRPCはバイナリでデータを転送するため、RESTful APIのようにJSONやXMLを使用する場合に比べて、デバッグが難しくなることがあります。 HTTP/2依存: gRPCはHTTP/2に依存しているため、HTTP/2をサポートしない環境では使用できない場合があります。 ブラウザサポートの制限:..
もっと見る- 191 ビュー
- 0 コメント
Friendly URLとは? SEOに優しいURLの最適化方法

Friendly URLとは? 今日のデジタル世界では、すべてのウェブサイトがGoogleやBing、Yahooなどの検索エンジンで目立ちたいと考えています。これを達成するためには、検索エンジン最適化(SEO)が非常に重要になります。 メタタグの有効活用をすることに加えて、SEO最適化でよく見落とされがちでありながら、実は非常に重要な要素が「Friendly URLs」の使用です。それでは、Friendly URLとは何であり、なぜそれが重要なのかを見ていきましょう。 Friendly URLの定義 Friendly URLは、人間と機械の両方にとって読みやすく理解しやすいウェブアドレスです。これらは通常、ページの内容に関連するキーワードを含み、論理的に組織されており、ユーザーと検索エンジンがURLだけでページの内容を簡単に理解できるようになっています。 なぜFriendly URLが重要なのか? 検索エンジンのインデックス性能向上:Friendly URLにはキーワードと明確な構造が含まれているため、検索エンジンがページ内容を簡単に分類して理解し、検索結果での表示を向上させることができます。 ユーザー体験の向上:読みやすく覚えやすいURLは、ユーザーがページに簡単に再訪問できるようにし、UXを改善するだけでなく、直帰率を減少させ、ページ滞在時間を増加させる可能性があります。 コンテンツ戦略のサポート:URLにキーワードを含めることで、SEOに最適化するだけでなく、ユーザーが注目すべき主要なテーマを強調することで、コンテンツ戦略を支援することができます。 Friendly URLとNon-Friendly URLの違い Friendly URLは、短く読みやすく、ページの内容を説明するキーワードを含んでいます。 例:https://example.com/tips-for-seo-success Non-Friendly URLは、ID番号やパラメータ、特殊文字など、不必要な多くの文字を含み、読みづらく覚えづらいものです。 例:https://example.com/index.php?page=123 Friendly URLへの変更は、SEOの改善だけでなく、ユーザー体験の向上にも貢献します。 Friendly URLの一般的なルール 効果的なキーワード選び: キーワード選定:URLにページ内容に関連するキーワードを選んで入れることは、特定の検索クエリで検索結果に表示される可能性を高めます。 URLの長さを最適化:短く覚えやすいURLは、ユーザーと検索エンジンの両方にとって便利であるため、URLにキーワードを含めるだけでなく、その長さにも注意が必要です。 単語をハイフンで区切る: 単語を区切る際には、アンダースコア(_)ではなくハイフン(-)を使用しましょう。Googleの検索エンジンはハイフンをスペースとして扱い、単語を区別するのに役立ちます。 特殊文字やエンコードを避ける: URLをシンプルに保つ:特殊文字やエンコード(例えば、%20は空白)を避けて、URLを混乱させないようにしましょう。これにより、ユーザーと検索エンジンの両方が理解しやすくなります。 明確な階層構造を持つ: コンテンツの整理:URL内で階層構造を使って、ウェブサイトのコンテンツ構造を反映させましょう。これにより、ユーザーと検索エンジンがコンテンツの整理方法を理解しやすくなります。 透明性と一貫性:URLの各部分が意味を持ち、ウェブサイト全体でURL構造が一貫していることを確認しましょう。 SEOに最適なFriendly URLの最適化方法 HTTPをHTTPSに変更 HTTPSの使用はSEOに有利です: GoogleはHTTPSをランキングアルゴリズムの要因として認識しています。SSLを使用するウェブサイトは、検索結果においてより関連性が高いとされています。 現代のブラウザは、HTTPSを使用していないウェブサイトにセキュリティ警告を表示することが多く、ユーザー体験に悪影響を及ぼします。HTTPSを使用することで、この問題を回避でき、ユーザーのクリック率が向上します。 理想的なURLの長さ GoogleはURLの長さをランキング要因として使用していません。しかし、50〜60文字以内の短いURLは読みやすく、検索結果に表示される際に切り取られることなく、ユーザーがページの内容を理解しやすくなります。また、Googlebotがデータをクロールしやすくなり、インデックスも早くなります。 Stop Wordsの使用を避ける SEOにおいて「Stop words」(「and」「or」「but」など)は通常、検索エンジンによって無視されるため、これらを避けることでURLを短縮し、キーワードを強調することができます。しかし、場合によってはStop wordsを保持することで、URLがより読みやすく、意味が明確になることがあります。 URLは最大2階層に保つ 複雑な階層URL:http://example.com/products/electronics/mobile-phones/smartphones/ 最適化されたURL:http://example.com/electronics/smartphones/..
もっと見る- 195 ビュー
- 0 コメント
Node.js/TypeScriptでのユーザー管理REST APIの構築(パート1:Express.js)

REST APIをNode.js/TypeScriptで構築する(パート1: Express.js) Node.jsでREST APIを構築する場合、リクエスト処理やルート管理を行うために、Express.jsは最もよく使われるフレームワークの一つです。Express.jsは小さなサイズで強力かつ柔軟な機能を提供し、プロジェクトに簡単に統合できます。このシリーズの記事では、Node.js/TypeScriptとExpress.jsを使ってユーザー管理のREST APIを構築する方法を紹介します。 使用するパッケージ: Express Typescript Cors: Expressのミドルウェアで、クロスオリジンリソースシェアリングを有効にするためのものです。 I. 必要なパッケージのインストールと初期設定 まず、以下のコマンドを実行します: npm init 次に、以下のコマンドで必要なパッケージをインストールします: npm i express cors さらに、開発用のパッケージも追加します: npm i –save-dev @types/cors @types/express typescript パッケージをインストールした後、`package.json`は以下のようになります(インストールする時期によってバージョンは異なります): II. プロジェクト構造 この段階での基本的なプロジェクト構造は、以下の2つのファイルで構成されます: app.ts users/users.routes.config.ts ここでは、各モジュールがその責任を持つようにプロジェクト構造を分けています。ユーザーモジュールには、ユーザー関連のロジックが含まれ、将来的にはユーザー以外のモジュールも作成することができます。 次回の記事では、ユーザーモジュールの中に`middleware`, `controllers`, `services`, `daos`, `dto` フォルダを追加し、各レイヤーの業務処理を明確に分ける方法を紹介します。 III. ルートとエントリーポイントapp.tsの実装 usersフォルダ内に`users.routes.config.ts`ファイルを作成し、以下のコードを記述します: import express from ‘express’; export class UsersRoutes { app: express.Application constructor(app:..
もっと見る- 134 ビュー
- 0 コメント
Laravel Octaneでアプリケーションのパフォーマンスを向上させる

Laravel Octane ご存知の通り、従来のLaravelアプリケーションでは、PHPは1回のリクエストを1回ずつ処理することしかできませんが、Laravel Octaneを使用すると、複数のリクエストを同時に処理できるようになり、ウェブサイトの速度が向上します。 1. Laravel Octaneとは? Laravel Octaneは、Laravelアプリケーションのパフォーマンスを向上させるために作成されたオープンソースのパッケージです。最初にアプリケーションを1回だけ起動し、それをメモリ(RAM)に保持し、その後のリクエストは、アプリケーションを最初から再起動するのではなく、メモリ内で保存された状態を再利用して処理されます。 Laravelのリクエストライフサイクル Laravel Octaneのリクエストライフサイクル Laravel Octaneのもう一つの特徴は、複数のワーカーを同時に使用してリクエストを処理できることです。これにより、以前のようにリクエストを1回ずつ処理するのではなく、複数のリクエストを同時に処理できるようになります。 Laravel Octaneのリクエスト処理の概要 Octaneは、FrankenPHP、Swoole、RoadRunnerという3つのPHPの非同期処理ツールを基盤として開発されています。この記事では、Swooleに焦点を当てます。 PHP Swooleは、Erlang、Node.js、Nettyの原則を基にPHP向けに設計されています。しかし、SwooleはLinuxカーネル上でのみ動作するため、現在はLinux、OS X、Cygwin、またはWSLでのみ使用できます。 2. PHP SwooleとPHP-FPMの違い 以下は、PHP SwooleとPHP-FPMの違いを比較した表です。 PHP Swoole PHP-FPM TCP、UDP、HTTP、HTTP2、Unixソケットのサポート あり なし。追加のライブラリが必要 非同期I/Oの使用 あり なし 各CPUに対してワーカープロセスの分割 – 同時処理のサポート あり なし PHPファイルをメモリに読み込む あり なし WebSocketサーバーやTCP/UDPサーバーのための長期接続サポート あり なし 3. Laravel OctaneとPHP-FPMの速度比較 Laravel Octaneの実力を証明するため、簡単なデモを行い、PHP OctaneとPHP-FPMの結果を比較してみましょう。 次のベンチマークテストを仮想マシン(VMware)で行いました: テストベンチの統計情報: CPU: 2コア(11th..
もっと見る- 1,031 ビュー
- 0 コメント
SEOウェブサイトでのMETAタグの効果的な使用

あなたが多くの技術を組み合わせてウェブサイトを最適化しようとしても、期待通りの結果が得られないことがあります。下記のようにMETAタグを活用することで、ウェブサイトのアクセスを迅速に改善できる方法を紹介します。 METAタグとは何ですか? METAタグ(Meta Tag)は、ウェブページの情報を検索エンジンに提供するためのHTMLタグです。これには、タイトル、著者、主要キーワード、内容の要約などの情報が含まれます。 METAタグは、SEOオンページの過程で重要な役割を果たします。 <html> <head> <meta http-equiv=”Content-Type” content=”text/html;charset=utf-8″> <title>Webike.vn | Webikeベトナムバイクコミュニティ</title> <meta name=”viewport” content=”width=device-width, initial-scale=1.0″> <meta name=”description” content=”Webike VNバイクコミュニティ – 2輪バイク、モーターサイクルの情報ページ、純正部品センター、最高のバイク販売市場” </head> </html> Googleがサポートする主要なMETAタグとSEOでの最適使用法 1. META Titleタグ META Titleは、現在の検索エンジン(Google、Bing、Yahooなど)の検索結果に表示されるタイトルです。 SEOにおいてMETA Titleは特に重要な役割を果たします。これは、検索エンジンにあなたの記事の内容を簡潔に伝える手段となります。 構文: <title> タイトル </title> META Titleを最適化する方法は? 最大60文字または580pxを含める SEO対象の主要キーワードを含める META Titleは記事の内容に関連している必要があります 行動を促す言葉を使う 企業のブランド名を含める 各ページに一意のMETA Titleを設定し、重複しないようにする 2. META Descriptionタグ META Descriptionは、検索結果ページ(SERP)でウェブサイトの下に表示される155〜160文字の説明です。META Descriptionは記事の内容を簡潔に要約し、検索エンジンや読者がウェブページのテーマを理解するのに役立ちます。 良いMETA Descriptionタグには次の3つの利点があります:..
もっと見る- 154 ビュー
- 0 コメント
PHPジェネレーター

こんな状況に直面したことはありませんか? これは、実行中のプロセスが許可されたRAMメモリ制限を超えてメモリを消費する場合に、PHP開発者が遭遇する可能性のあるエラーです。 具体的な例を見てみましょう: private function range() { $a = []; for ($i = 0; $i < PHP_INT_MAX; $i++) { $a[] = $i; } return $a; } foreach ($this->range() as $value) { echo $value; } 上記のコードは、0からPHP_INT_MAX(現在のPHPバージョンが提供する最大の整数値)までの配列を作成し、その値を画面に出力します。コードを実行すると、先に述べたエラーが発生します。 このエラーに対処する方法はどうすれば良いのでしょうか?一つの方法は、“memory_limit”の設定をphp.iniファイルで増加させることです。 ; スクリプトが消費する最大メモリ量 ; https://php.net/memory-limit memory_limit = 128M しかし、これは最適な解決策ではありません。小さなコードでメモリ制限オーバーエラーが発生しているのは問題があります。そこで、メモリ制限を増加させる代わりに、PHPジェネレーターを使用して、どのようにメモリ使用量を削減できるか試してみましょう。 PHPジェネレーターとは? PHPジェネレーターは、PHP 5.5で導入された強力な機能です。この機能により、ジェネレーター関数を作成することができ、ジェネレーター関数はすべての値を一度に返すのではなく、必要に応じて1つずつ値を生成して返します。これによりメモリを大幅に節約でき、データセット全体をメモリに保持せずにデータを処理することができます。 PHPジェネレーターの使用方法 上記のコードで、“range()”関数を変更して、配列(文字列)を作成してすべての値を返すのではなく、yieldキーワードを使って値を順番に返すようにします。簡単に言うと、yieldは値を返しますが、すべての値をメモリに保存することなく、その時点で呼び出すときにのみ値を返します。このようにすると、関数はジェネレーター関数になります。 private function range() { for ($i..
もっと見る- 155 ビュー
- 0 コメント
Prometheus/Loki/Grafanaを使用したシステム監視のセットアップとモニタリング(パート2)

パート1では、企業が監視システムを導入しない、または効果的な監視が行われない場合に発生するリスクと影響について説明しました。また、監視対象のシステムのサーバーをセットアップする方法も紹介しました。パート2では、サーバーモニターのセットアップ方法をさらに詳しく説明し、監視システムの完成を目指します。 ただし、軽量なアプリケーションを作成するためには、いくつかのコツが必要です。 システム監視モデルの展開(続き) 2. サーバーモニターの設定 必要なツール:Prometheus、Loki、Grafana a. Prometheusのインストール ダウンロードとインストールの手順: # Prometheus用のフォルダを作成 $ mkdir /usr/local/src/prometheus # 作成したフォルダに移動 $ cd /usr/local/src/prometheus # 最新のPrometheusをダウンロード $ wget https://github.com/prometheus/prometheus/releases/download/v2.46.0/prometheus-2.46.0.linux-amd64.tar.gz # ダウンロードしたファイルを解凍 $ tar zxvf prometheus-2.46.0.linux-amd64.tar.gz $ mv prometheus-2.46.0.linux-amd64 prometheus # /usr/binに移動 $ cp -r prometheus/prometheus /usr/bin 設定ファイルをダウンロードし、必要に応じて設定を調整します: # 設定ファイル用のフォルダを作成し、設定ファイルをダウンロード $ mkdir /etc/prometheus $ cd /etc/prometheus $ wget https://raw.githubusercontent.com/prometheus/prometheus/master/documentation/examples/prometheus.yml 設定ファイルの内容を以下のように調整します: #..
もっと見る- 576 ビュー
- 0 コメント
Dockerイメージのビルドのコツ

Dockerは、アプリケーションをさまざまな環境で柔軟かつ効率的に構築、展開、管理するためのオープンソースの仮想化プラットフォームです。Dockerを使用することで、ソースコード、ライブラリ、環境変数、設定ファイルなど、アプリケーションに必要なすべてのコンポーネントを独立したコンテナにパッケージ化することができます。 しかし、軽量なアプリケーションをビルドするためには、いくつかのコツが必要です。 公式イメージを使用する 現在のDockerの普及により、多くのソフトウェアベンダーが独自のイメージを提供しています。公式イメージを使用することで、以下の利点があります: Dockerfileがシンプルになる ビルドが安定する(ベンダーがリリース前にテストを行っている) 生成されるイメージのサイズが小さくなる(ベンダーが最適化済み) 最新イメージの使用を避ける ソフトウェアベンダーが新しいバージョンをリリースする際、通常、新機能が追加され、古い機能が削除されます。そのため、latestイメージを使用すると、ビルドのたびにシステムが不安定になる可能性があります。 Alpineイメージを選択する Alpine Linuxの主な理念は小さく、シンプルで、安全であることです。そのため、多くのソフトウェアベンダーがAlpine Linuxを基盤にしたイメージを提供しています。Alpineイメージは、システムが安定して動作するために必要な機能を提供します。 ただし、Alpineイメージを使用する際は、ライブラリが不足している点に注意が必要です。これはAlpineの軽量化のため、最小限のライブラリしか提供されていないためです。 Alpine以外では、Docker Images SlimやDocker Cloudも良い選択肢です。使用するケースに応じて選びましょう。 レイヤーキャッシュの活用 Dockerを使用していると、イメージのビルドが頻繁に行われます。最適化されたイメージをビルドしたり、不要なライブラリを更新したり、CI/CDプロセスを通じてリリースする場合です。毎回Dockerfileを再実行しないように、Dockerはレイヤーキャッシュ機能を提供しています。 イメージをビルドするとき、Dockerは以前のビルドをチェックします。レイヤーに変更がない場合、そのレイヤーはキャッシュから再利用されます。レイヤーに変更があった場合、そのレイヤー以降は再ビルドされます。 上記のように、プロジェクト内でファイルが変更された場合、composer installコマンドが再実行されます。 composer.jsonとcomposer.lockファイルは変更されることが少ないため、過去のビルドからパッケージをインストールすることができます。 レイヤーを操作するときは、変更の少ないビルドコマンド(パッケージのインストール、composer、nodeなど)を上部に配置し、頻繁に変更されるコマンドを下部に配置します。 レイヤー数を減らす Dockerイメージのサイズを決定する要因の一つにレイヤーの数があります。多くのレイヤーを追加すると、イメージのサイズが大きくなります。イメージを作成するコマンド(RUN、COPY、ADD)がレイヤーを作成します。 アドバイスとしては、&&を使って複数のコマンドを1つにまとめ、レイヤー数を減らすことです。 上記の例では、9つのレイヤーを作成する代わりに、&&を使用してレイヤー数を減らしました。複雑なシステムの場合、レイヤー数を減らすことでイメージのサイズを大幅に削減できます。 ただし、コマンドをまとめることで、レイヤーキャッシュ機能が失われます。わずかな変更でも再ビルドが必要になるため、レイヤーの追加や削除は慎重に行う必要があります。 結論 小さなイメージを作成することで、システムの展開が速くなり、システムの起動時間が改善され、セキュリティホールが減少します。Dockerイメージの最適化には時間と労力がかかりますが、それによって得られる利益は計り知れません。 Vũ Khắc Nguyễn Web Developer
もっと見る- 340 ビュー
- 0 コメント

福利厚生

社員の感情・願望を理解しているので、リバークレーンベトナムは特に年2回の定期昇給制度を設けています。毎年6月と12月に評価を行い、毎年1月と7月に給与が変更されます。また、社員は月次と年次の優秀な個人には定期的な業績賞与が別で支給されます。



チームビルディング・ファミリーデー・お夏休み・中秋節などのイベントはチーム内のメンバーが接続出来るしお互いに自分のことを共有出来る機会です。ご家族員に連携する際にはそれも誇りに言われています。



