Google Cloud Dataflowの強力な機能を探る
Google Cloud Dataflowの概要
定義と主な機能
Google Cloud Dataflowは、クラウドプラットフォーム上で完全に管理されたリアルタイムおよびバッチデータ処理サービスです。開発者や企業は、複雑なインフラストラクチャを管理することなく、スケーラブルで効率的なデータ処理パイプラインを構築することができます。
Google Cloud Dataflowの主な機能は以下の通りです:
- リアルタイムおよびバッチデータ処理。
- リソースの自動スケーリングと管理。
- JavaやPythonなど、多くのプログラミング言語をサポート。
- 他のGoogle Cloudサービスとのシームレスな統合。
他のデータ処理ソリューションとの比較
| 特徴 | Google Cloud Dataflow | Apache Spark | Apache Flink |
| 処理モデル | リアルタイムおよびバッチ | 主にバッチ | リアルタイムおよびバッチ |
| 管理 | 完全に管理されている | 自己管理 | 自己管理 |
| スケーラビリティ | 自動 | 手動 | 手動 |
| サポート言語 | Java, Python | Scala, Java, Python, R | Java, Scala |
| クラウド統合 | GCPとの深い統合 | 複数のプラットフォームをサポート | 複数のプラットフォームをサポート |
Dataflowを使用する利点
- 高パフォーマンス:Dataflowはデータ処理パイプラインを自動的に最適化し、最大限のパフォーマンスを提供します。
- コスト削減:柔軟な料金モデルと自動スケーリング機能により、運用コストを削減できます。
- 開発が容易:バッチおよびリアルタイム処理のためのシンプルで統一されたプログラミングモデル。
- スケーラビリティ:データ処理の急増に対応するために自動的にスケールします。
- 高い信頼性:システムは自動的にエラーを処理し、データの一貫性を保証します。
これらの利点により、Google Cloud Dataflowは、強力で柔軟なクラウドベースのデータ処理システムを構築したい企業にとって魅力的な選択肢となります。次に、Google Cloud Dataflowのアーキテクチャとコアコンポーネントについて詳しく見ていきます。
Google Cloud Dataflowのアーキテクチャとコンポーネント
スケーラビリティと柔軟性
Google Cloud Dataflowは、高いスケーラビリティと柔軟性を持つように設計されており、大規模なデータ処理を効率的に実行できます。システムはワークロードに基づいてリソースを自動的に調整し、最適なパフォーマンスとコスト削減を実現します。
他のGoogle Cloudサービスとの統合
Dataflowは、多くのGoogle Cloudサービスとシームレスに統合されており、データ処理と分析のための強力なエコシステムを構築します。以下は、Dataflowといくつかの主要サービスとの統合比較表です:
| Google Cloudサービス | Dataflowとの統合 |
| BigQuery | データのインポート/エクスポート |
| Cloud Storage | 入力/出力データの保存 |
| Pub/Sub | リアルタイムデータストリームの処理 |
| Cloud Spanner | データベースのクエリと更新 |
Dataflowの主なコンポーネント
Google Cloud Dataflowは、次の主要なコンポーネントを含んでいます:
- Pipeline:データ処理のロジックを定義します。
- PCollection:入力および出力データセットを表します。
- Transform:データの変換操作。
- SourceとSink:データの入力元と結果の保存先を定義します。
データ処理モデル
Dataflowは、以下の2つの主要なデータ処理モデルをサポートします:
- バッチ処理:静的データのバッチ処理。
- ストリーミング処理:リアルタイムデータの処理。
柔軟なアーキテクチャと強力なコンポーネントを備えたGoogle Cloud Dataflowは、複雑なデータ処理パイプラインを構築するための堅実な基盤を提供します。次に、Dataflowの優れた特徴について詳しく見ていきます。
Google Cloud Dataflowの特徴
Google Cloud Dataflowは、Google Cloudのデータ処理エコシステム内で強力なツールです。その力強さを支える主要な特徴を見ていきましょう。
統一されたプログラミングモデル
Google Cloud Dataflowは、バッチデータ処理とリアルタイム処理の両方に対応した統一されたプログラミングモデルを提供します。これにより、開発者は両方の処理タイプに同じコードベースを使用でき、開発とメンテナンスの時間と労力を節約できます。
多様なデータ処理能力
Dataflowは、構造化データから非構造化データまで、多くの異なる種類のデータを処理できます。以下のような多様なデータソースをサポートしています:
- リレーショナルデータベース。
- NoSQLデータベース。
- ファイルシステム。
- APIからのデータ。
パイプラインの自動最適化
Dataflowの最も印象的な機能の1つは、パイプラインを自動的に最適化する能力です。システムは以下を行います:
- データフローの解析。
- ボトルネックを特定。
- リソースを自動的に調整。
これにより、ユーザーの手動介入なしで最適なパフォーマンスが確保されます。
バッチデータ処理
Dataflowは強力なバッチデータ処理機能を提供し、大量の静的データを効率的に処理します。以下のタスクをサポートしています:
- 履歴データの分析。
- 定期レポートの作成。
- バッチデータの処理。
リアルタイムデータ処理
最後に、Dataflowはリアルタイムデータ処理にも優れています。これにより、次のことが可能になります:
| 特徴 | 説明 |
| ストリーム処理 | 生成されるデータをリアルタイムで処理 |
| リアルタイム分析 | 即時のインサイト提供 |
| 迅速な反応 | 最新のデータに基づいて意思決定を行う |
これらの強力な機能により、Google Cloud Dataflowは大規模データ処理に欠かせないツールとなっています。次に、さまざまな業界でのDataflowの実際の使用例を見ていきます。
Google Cloud Dataflowの実際の使用例
Google Cloud Dataflowは、多くの実際のアプリケーションでその柔軟性と効率を証明しています。以下は、この強力なツールの注目すべき使用例です。
A. 機械学習とAIシステムの構築
Google Cloud Dataflowは、機械学習(ML)および人工知能(AI)システムの構築と展開において重要な役割を果たします。データの大規模処理を提供し、開発者が次のことを実行できるようにします:
- 入力データの前処理とクレンジング。
- 特徴の抽出と変換。
- ML/AIモデルの訓練と評価。
| 利点 | 説明 |
| シームレスな統合 | Google CloudのML/AIサービスとの簡単な接続 |
| バッチおよびストリーミング処理 | バッチ処理とリアルタイム処理の両方をサポート |
| スケーラビリティ | ワークロードに合わせてリソースを自動調整 |
B. データの統合と変換
Dataflowは、さまざまなソースからのデータ統合と変換に強力なツールです。一般的な使用例は以下の通りです:
- 大規模なETL(抽出、変換、ロード)処理。
- システム間のデータ同期。
- データの正規化とクレンジング。
C. IoTデータ処理
IoT分野では、Dataflowはセンサーデバイスからの膨大なデータを処理する重要な役割を担っています。次のことを実行できます:
- 何百万ものデバイスからのリアルタイムデータ処理。
- 異常検出と警告。
- IoTデータの集約と分析。
D. 大規模データ分析
最後に、Dataflowは大規模データ分析に理想的なツールであり、次の機能を提供します:
- ペタバイト規模のデータ処理能力。
- 効率的な分散計算。
- データ分析および可視化ツールとの統合。
これらの多様な用途により、Google Cloud Dataflowは多くの企業にとって不可欠なツールとなり、データの力を最大限に活用しています。次に、Google Cloud Dataflowを使い始める方法を見ていきましょう。
Google Cloud Dataflowの使用開始
A. ドキュメント
Google Cloud Dataflowは、開始するための豊富なドキュメントと学習リソースを提供しています。Google Cloud Dataflowの公式サイトは、概要、ガイド、APIリファレンスを提供しており、優れた出発点となります。また、GoogleはGoogle Cloud Trainingを通じて、無料で証明書が取得できるオンラインコースも提供しています。
https://cloud.google.com/dataflow/docs/overview
B. サポートツールとSDK
Google Cloud Dataflowは、パイプライン開発のために多くのツールとSDKをサポートしています:
- Apache Beam SDK:Java、Python、Goをサポート。
- Google Cloud Console:Dataflowジョブの管理と監視用のウェブインターフェース。
- Google Cloud SDK:Dataflowとの対話のためのコマンドラインツール。
| ツール | サポートされている言語 | 使用目的 |
| Apache Beam SDK | Java, Python, Go | パイプライン開発 |
| Google Cloud Console | Webインターフェース | 管理と監視 |
| Google Cloud SDK | コマンドライン | Dataflowとの対話 |
C. 初めてのパイプラインの作成と実行
最初のパイプラインを作成し、実行するには、以下の手順を実行する必要があります:
- Apache Beam SDKをインストールします。
- Beam SDKを使用してパイプラインコードを書く。
- Dataflowパラメータを設定する。
- Google Cloud Dataflowでパイプラインを実行する。
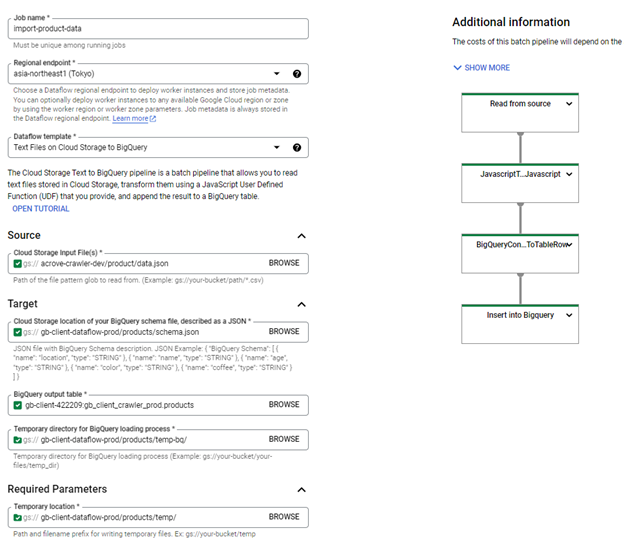
D. Dataflowジョブのデプロイ(GCSデータをBigQueryにインポート)
- Googleが提供するテンプレートを使用(Text Files on Cloud Storage to Big Query)。
- GCP Dataflowコンソールにアクセス。
- Dataflowジョブ作成フォームに情報を入力。
| 属性 | 値 | 説明 |
| Job名 | import-product-data | Dataflowジョブ名 |
| リージョナルエンドポイント | asia-northeast1 (Tokyo) | Dataflowリージョン |
| Dataflowテンプレート | Text Files on Cloud Storage to Big Query | Cloud Storageに保存されたテキストファイルを読み込み、指定されたJavaScript UDFで変換し、BigQueryに追加するテンプレート。 |
| Cloud Storage Input File Pattern | gs://{data_bucket_name}/sample-data/*.jsonl | データファイル形式 |
| Cloud StorageのBQスキーマ場所 | gs://{dataflow_bucket_name}/products/schema.json | BigQueryスキーマJSONファイル |
| BQ出力テーブル | {PROJECT_ID}:{dataset}.{table} | BigQueryテーブル |
| BQローディングプロセス用の一時ディレクトリ | gs://{dataflow_bucket_name}/products/temp-bq/ | BigQueryへのデータ読み込み一時ディレクトリ |
| 一時場所 | gs://{dataflow_bucket_name}/products/temp/ | 一時ファイルの保存先ディレクトリとプレフィックス |
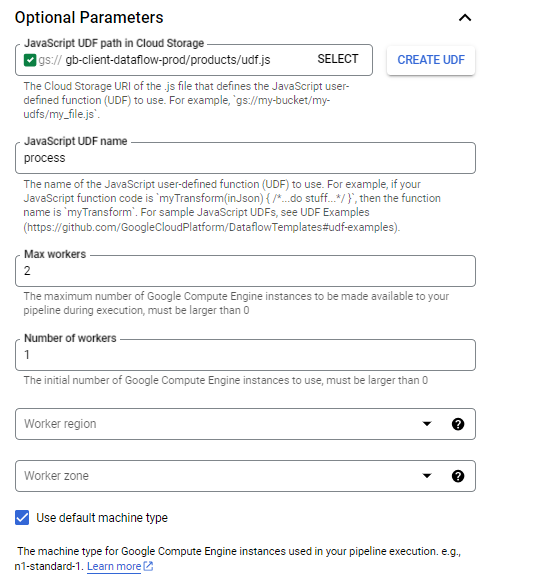
| Cloud StorageにおけるJavaScript UDFのパス | gs://{dataflow_bucket_name}/products/udf.js | ユーザー定義JavaScript UDFのCloud Storage内のURI |
| JavaScript UDF名 | process | ユーザー定義JavaScript UDFの関数名 |
| 最大ワーカー数 | 2 | ジョブ実行時に使用する最大Google Compute Engineインスタンス数(0より大きい必要があります) |
| ワーカー数 | 1 | 初期Google Compute Engineインスタンス数(0より大きい必要があります) |
たとえば、次のようなjsonlデータファイルがあります (gs://{data_bucket_name}/sample-data/data.jsonl):
{“name”: “Nguyễn A”, “age”: “20”} {“name”: “Trần B”, “age”: “25”}
次に、Dataflowジョブの設定コードは以下の通りです:
1. BigQueryスキーマファイル (gs://{dataflow_bucket_name}/products/schema.json)
{ “BigQuery Schema”: [ { “name”: “name”, “type”: “STRING” }, { “name”: “age”, “type”: “INTEGER” }, ] }
2. UDF関数
{ function process(inJson) { val = inJson.split(“,”); const obj = { “name”: val[0], “age”: parseInt(val[1]) }; return JSON.stringify(obj); } }
その後、「ジョブの実行」ボタンをクリックします。
Dataflowジョブが開始され、その進行状況はジョブ詳細画面に表示されます:
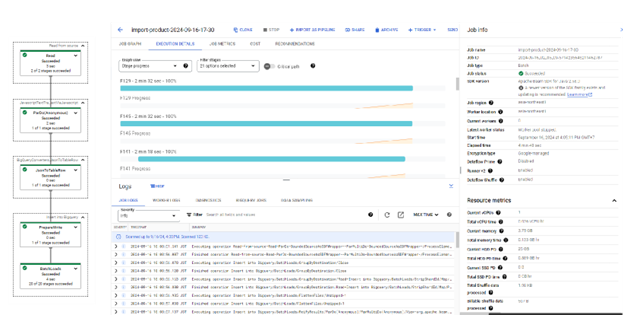
すべてのプロセスが正常に実行されると、BigQueryテーブルでデータを確認できます。
まとめ
Google Cloud Dataflowは、大規模データ処理のための強力なツールであり、リアルタイムおよびバッチ処理に対応しています。柔軟なアーキテクチャと統一されたプログラミングモデル、自動最適化、そして自動スケーリングなどの優れた特徴を備えており、複雑なデータ処理ニーズに対応します。
Google Cloud Dataflowの力を活用することで、企業や開発者はインフラストラクチャに気を使うことなく、創造的なデータソリューションを構築できます。適切に設定された開発環境で、Dataflowパイプラインの開発とデプロイを効果的に開始できます。今すぐGoogle Cloud Dataflowを使い始め、データ処理の可能性をプロジェクトに活かしてください。
 | Nguyễn Xuân Việt Anh Developer |
今すぐ応募
福利厚生

社員の感情・願望を理解しているので、リバークレーンベトナムは特に年2回の定期昇給制度を設けています。毎年6月と12月に評価を行い、毎年1月と7月に給与が変更されます。また、社員は月次と年次の優秀な個人には定期的な業績賞与が別で支給されます。



チームビルディング・ファミリーデー・お夏休み・中秋節などのイベントはチーム内のメンバーが接続出来るしお互いに自分のことを共有出来る機会です。ご家族員に連携する際にはそれも誇りに言われています。



